sort
-
[Algorithm] Merge Sort (합병 정렬) C++2021.07.25
-
[Algorithm] Bubble Sort (버블 소트) C++2021.07.23
-
[Algorithm] Selection Sort (선택 정렬) C++2021.07.22
-
[Algorithm] Insertion Sort (삽입 정렬) C++2021.07.20
[Algorithm] Merge Sort (합병 정렬) C++
본 블로그에서 이미 다룬 선택, 삽입, 버블 정렬 돠 비교하면 이해하기 다소 높은 정렬 알고리즘이라고 할 수 있다.
합병 정렬은 divide and conquer (분할 정복) 알고리즘을 기반으로 정렬을 하는 알고리즘이다.
Divide and conquer 알고리즘은 큰 문제를 작은 문제들로 쪼개서 해결하는 방식이다. 합병 정렬에서는 배열을 계속 쪼개 작은 행렬들을 정렬하고 그 행렬들을 합쳐 정렬을 진행한다. (해당 알고리즘에 대해서 따로 포스팅할 예정이다).
합병 정렬은 정렬을 하는 배열외의 추가적인 임시 배열 (추가적인 메모리)가 필요하다. 삽입, 버블, 선택 정렬의 공간 복잡도 $O$($1$) 과 다르게 합병 정렬은 정렬하고자 하는 배열의 크기만큼의 추가적인 크기가 요구되기 때문에 $O$($n$)의 공간복잡도를 가진다. 또한 In-place 알고리즘이 아니다.
합병 정렬은 배열은 $log$ $n$번 쪼개어 대수 비교를 하기 때문에 시간 복잡도는 $O$($nlog$ $n$)이다. 예를 들어 원소가 8개인 배열을 중간 원소를 기준으로 3번 쪼개면 8개 원소가 1개씩으로 쪼개진다.

합병 정렬의 작동 방법
- 배열을 원소의 개수가 1인 그룹으로 재귀적 호출을 이용해 나눈다.
- 인접한 그룹을 의 첫번째 원소부터 끝 원소까지 대소 비교를 하여 정렬된 하나의 그룹을 만든다. 정렬된 새로운 그룹(배열)을 전역 변수 정수형 임시 배열에 저장한다.
- 전역 변수 정수형 임시 배열을 원래 배열에 복사한다.
합병 정렬 추천 이해 루트
필자는 머리가 나쁘기 때문에 머지 소트를 이했던 방법에 대해서 설명한다.
- 배열이 재귀호출로 분할되는 과정을 이해한다.
- 재귀호출로 스택에 쌓이는 순서를 이해한다.
- 작게 쪼개진 배열의 대소비교를 이해한다.
배열의 대소비교 로직은 쉬우니 재귀호출이 스택에 어떻게 쌓이고 어떤 순서로 대소비교가 되는지를 알면 합병 정렬을 이해하기 쉽다.
합병 정렬의 시간, 공간 복잡도
| 시간 복잡도 | 공간 복잡도 | ||
| 평균 (Average) | 최선 (Best) | 최악 (Worst) | |
| $O$($nlog$ $n$) | $O$($nlog$ $n$) | $O$($nlog$ $n$) | $O$($n$) |
Merge Sort (합병 정렬) C++ 코드
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int* sorted;
void merge(int* arr, int left, int right)
{
int mid = (left + right) / 2;
int i = left;
int j = mid + 1;
//i ~ mid을 한 그룹 mid + 1 ~ right를 한 그룹으로 나눠서 처리.
int index_sorted = left;
while (i <= mid && j <= right)
{
if (arr[i] > arr[j])
{
sorted[index_sorted++] = arr[j++];
}
else
{
sorted[index_sorted++] = arr[i++];
}
}
if (i > mid)
{
while (j <= right)
{
sorted[index_sorted++] = arr[j++];
}
}
else
{
while (i <= mid)
{
sorted[index_sorted++] = arr[i++];
}
}
//arr에 재배치된 배열 업데이트
for (int a = left; a <= right; ++a)
{
arr[a] = sorted[a];
}
}
void partition(int* arr, int left, int right)
{
int mid;
if (left < right)
{
mid = (left + right) / 2;
partition(arr, left, mid);
partition(arr, mid + 1, right);
merge(arr, left, right);
}
}
int main()
{
int* arr;
srand(unsigned int(time(NULL)));
int amount;
cout << "amout : ";
cin >> amount;
arr = new int[amount];
sorted = new int[amount];
int i;
for (i = 0; i < amount; ++i)
{
arr[i] = rand() % 10;
sorted[i] = 0;
}
for (i = 0; i < amount; ++i)
cout << arr[i] << " ";
cout << '\n';
partition(arr, 0, amount - 1);
for (i = 0; i < amount; ++i)
cout << arr[i] << " ";
cout << '\n';
}
고찰
divide and conquer에 대해서 처음 배우게 되어서 조금 시간이 많이 걸렸다. 먼저 재귀함수에 대해서 전체적으로 돌아가는 로직은 알았으나 세부적으로 스택에 어떻게 쌓여서 어떤 우선순위로 일이 처리되는지 잘 이해하지 못해서 조금 힘들었다. 해당 정렬을 정리하면서 스택의 LIFO에 대해서도 조금 더 알게 되었다.
Ref.
Merge Sort / https://en.wikipedia.org/wiki/Merge_sort
'Algorithm' 카테고리의 다른 글
| [Algorithm] Shell Sort (쉘 정렬) C++ (0) | 2021.08.08 |
|---|---|
| [Algorithm] Quick Sort (퀵 정렬) C++ (0) | 2021.08.01 |
| [Algorithm] Bubble Sort (버블 소트) C++ (0) | 2021.07.23 |
| [Algorithm] Selection Sort (선택 정렬) C++ (0) | 2021.07.22 |
| [Algorithm] Insertion Sort (삽입 정렬) C++ (0) | 2021.07.20 |
[Algorithm] Bubble Sort (버블 소트) C++
거품 정렬 혹은 버블 소트라고 불리는 Bubble Sort는 개인적으로 구현하기 가장 쉬운 알고리즘이다. 그렇기 때문에 현재 필자가 가장 많이 사용하는 정렬 알고리즘이다.
버블 소트는 왼쪽부터 작은 원소를 하나씩 정렬시키는 정렬이다. 그렇게 하기 위해서 반대쪽 원소부터 왼쪽까지 인접한 원소끼리 대소 비교 및 교환한다.
버블 소트는 구현하기 쉬운 장점이 있지만 불필요한 교환이 이루어진다는 점이 단점이다.
버블 소트의 작동 방법
- 0번째 원소부터 N - 1번째 원소를 기준으로 잡는다.
- 최우단에서부터 인접한 원소들의 대소 비교를 통하여 작은 원소를 기준이 되는 위치에 정렬한다
버블 소트의 시간, 공간 복잡도
| 시간 복잡도 | 공간 복잡도 | ||
| 평균 (Average) | 최선 (Best) | 최악 (Worst) | |
| $O$($n^2$) | $O$($n^2$) | $O$($n^2$) | $O$($1$) |
Bubble Sort (버블 소트) C++ 코드
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
void SWAP(int* a, int* b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void BubbleSort(int* arr, int max_vol)
{
int i, j;
for (i = 0; i < max_vol; ++i)
{
for (j = max_vol - 1; j > i; --j)
{
if (arr[j] < arr[j - 1])
{
SWAP(&arr[j], &arr[j - 1]);
}
}
}
}
int main()
{
srand(unsigned int(time(NULL)));
int arr[10] = { 0, };
int i = 0;
for (i = 0; i < 10; ++i)
{
arr[i] = rand() % 100;
}
for (i = 0; i < 10; ++i)
cout << arr[i] << " ";
cout << '\n';
BubbleSort(arr, 10);
for (i = 0; i < 10; ++i)
cout << arr[i] << " ";
cout << '\n';
}
Ref.
Bubble sort / https://en.wikipedia.org/wiki/Bubble_sort
'Algorithm' 카테고리의 다른 글
| [Algorithm] Quick Sort (퀵 정렬) C++ (0) | 2021.08.01 |
|---|---|
| [Algorithm] Merge Sort (합병 정렬) C++ (0) | 2021.07.25 |
| [Algorithm] Selection Sort (선택 정렬) C++ (0) | 2021.07.22 |
| [Algorithm] Insertion Sort (삽입 정렬) C++ (0) | 2021.07.20 |
| [Algorithm] Asymptotic Notation(점근 표기법) : Big - O Notation(빅 - 오 표기법) (0) | 2021.07.18 |
[Algorithm] Selection Sort (선택 정렬) C++
선택정렬은 사람이 정렬하는 방법과 가장 유사한 정렬 알고리즘이다.
0번째 원소부터 N - 1번째 뭔소 기준으로 우측 원소들의 가장 작은값과 대소비교를 하여 교환을 해주는 방식이다.
선택정렬은 모든 경우에서 $O(n^2)$이라는 느릭 속도를 자랑하지만 선택 정렬 또한 특정 경우에 뛰어난 퍼포먼스를 보여주는 경우가 존재한다.
일단 첫번째로는 사람의 정렬 방법과 유사하다는 점에서 단순하다는 점이 장점이다. 또, 가용한 메모리가 한정적인 경우에서 in-place 알고리즘이기 때문에 효과적이다. (in-place 알고리즘에 대해서 나중에 자세하게 다뤄본다). descending -order (내림차순)으로 정렬된 데이터에 대해서 Ascending - order(오름차순)으로 정렬할 경우 최적의 효율을 낸다.
물론 선택정렬은 느린 정렬에 속한다. (자주 사용되는 정렬을 모두 정리한 다음에 특정 케이스에 대해서 적합한 정렬에 대해서 포스팅할 예정이다)
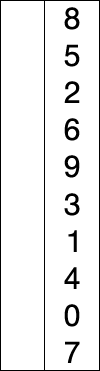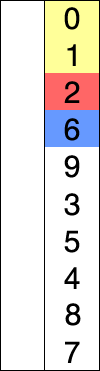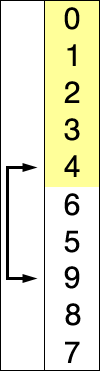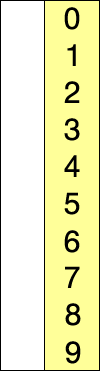
참고 https://en.wikipedia.org/wiki/Selection_sort
선택 정렬의 작동 방법
- 0번째 원소부터 N - 1번째 원소를 기준으로 우측 원소들에서 가장 작은 원소를 integer형 변수 min_vol에 저장한다.
- 기준이 되는 원소와 min_vol의 대수비교를 통해 기준 원소가 min_vol보다 크다면 두 원소를 SWAP함수를 통해 교환한다.
선택 정렬의 시간, 공간 복잡도
| 시간 복잡도 | 공간 복잡도 | ||
| 평균 (Average) | 최선 (Best) | 최악 (Worst) | |
| $O$($n^2$) | $O$($n^2$) | $O$($n^2$) | $O$($1$) |
Selection Sort (선택 정렬) C++ 코드
#include <iostream>
#include <ctime>
#include <cstdlib>
using namespace std;
void SWAP(int* a, int* b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
void SelectionSort(int* arr, int max_vol)
{
int min;
int i, j;
for (i = 0; i < max_vol - 1; ++i)
{
min = i + 1;
for (j = i + 1; j < max_vol; ++j)
{
if (arr[min] > arr[j])
min = j;
}
if (arr[i] > arr[min])
SWAP(&arr[i], &arr[min]);
}
}
int main()
{
srand(unsigned int(time(NULL)));
int arr[10] = { 0, };
int i;
for (i = 0; i < sizeof(arr) / sizeof(int); ++i)
arr[i] = rand() % 100;
cout << "before sort\n";
for (i = 0; i < sizeof(arr) / sizeof(int); ++i)
cout << arr[i] << " ";
cout << '\n';
SelectionSort(arr, sizeof(arr) / sizeof(int));
cout << "after sort\n";
for (i = 0; i < sizeof(arr) / sizeof(int); ++i)
cout << arr[i] << " ";
cout << '\n';
}
고찰
각 정렬의 장단점에 대해서 공부를 하고있지만 막상 코딩을 할 때 어떤 상황에서 어떤 정렬 알고리즘을 사용해야 하는지 판단이 안 설 것 같다. 시간, 공간복잡도에 대해서도 이해도가 깊지 않을 것 같아서 따로 시간을 들여서 공부가 필요할 것 같다.
Ref.
Selection Sort / https://en.wikipedia.org/wiki/Selection_sort
'Algorithm' 카테고리의 다른 글
| [Algorithm] Quick Sort (퀵 정렬) C++ (0) | 2021.08.01 |
|---|---|
| [Algorithm] Merge Sort (합병 정렬) C++ (0) | 2021.07.25 |
| [Algorithm] Bubble Sort (버블 소트) C++ (0) | 2021.07.23 |
| [Algorithm] Insertion Sort (삽입 정렬) C++ (0) | 2021.07.20 |
| [Algorithm] Asymptotic Notation(점근 표기법) : Big - O Notation(빅 - 오 표기법) (0) | 2021.07.18 |
[Algorithm] Insertion Sort (삽입 정렬) C++
필자가 항상 헷갈려 하는것이 정렬 알고리즘이다.
이제까지 속도를 고려하지 않고 Bubble Sort가 손에 익기 때문에 사용을 해왔다. 이제 제대로 공부할 시기가 왔기도 했고 백준 문제를 풀때 정렬 속도 때문에 틀리는 경우가 빈번해 졌기 때문에 이번 기회에 하나씩 구현해보면서 손에 익히는 과정을 가지도록한다.
삽입 정렬은 최선의 케이스에서 시간 복잡도가 $O$($n$)라는 빠른속도를 가지고 있지만 최악의 케이스에서는 $O$($n^2$)라는 느린 속도를 가진다.
삽입 정렬은 이미 정렬된 데이터를 정렬할때 매우 유용하게 사용된다.

삽입 정렬의 작동 방법
- integer형 배열의 1번째(2번째 원소)원소의 값을 integer형 변수 Key에 저장한다.
- 해당 원소기준 왼쪽부터 자신과 대소 비교를 하여 자신보다 작은 원소를 만날때 까지 원소를 오른쪽으로 이동시킨다.
- 해당 자리에 Key값을 저장시킨다.
- 다음 원소를 Key값에 새로 저장하고 마지막 원소까지 위 과정을 반복한다. Loop (1번째 원소 ~ 마지막 원소)
삽입 정렬의 시간, 공간 복잡도
| 시간 복잡도 | 공간 복잡도 | ||
| 평균 (Average) | 최선 (Best) | 최악 (Worst) | |
| $O$($n^2$) | $O$($n$) | $O$($n^2$) | $O$($1$) |
Insertion Sort(삽입 정렬) C++ 코드
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
void InsertionSort(int* sort_arr, int index)
{
int i, j;
for (i = 1; i < 10; ++i)
{
int target = sort_arr[i];
for (j = i - 1; j >= 0 && sort_arr[j] > target; --j)
{
sort_arr[j + 1] = sort_arr[j];
}
sort_arr[j + 1] = target;
}
}
int main()
{
srand((unsigned int)time(NULL));
int arr[10];
int i;
for (i = 0; i < 10; ++i)
arr[i] = rand() % 100; //0 ~ 99
cout << "before sort\n";
for (i = 0; i < 10; ++i)
cout << arr[i] << ' ';
cout << '\n';
cout << "after sort\n";
InsertionSort(arr, 10);
for (i = 0; i < 10; ++i)
cout << arr[i] << ' ';
cout << '\n';
}
고찰
정렬에 대해서 별로 크게 의미를 두지 않았다. 왜냐하면 문제가 주어지면 해당 문제를 푸는 과정에 있어서 정렬 알고리즘은 그냥 작은 일부분이라고 생각했고 "정렬만 되만 되지"라는 생각을 가지고 있었다. 거기에 정렬 마다 속도가 빠르고 느리다는 생각을 가지고 있었지만 삽입 정렬은 느린 정렬 퀵 정렬은 빠른 정렬이라고만 생각하고 있었는데 삽입 정렬이 가장 효율이 좋을때도 있다는 사실을 공부하고 살짝 충격을 먹었다. 각 정렬마다 장단점을 파악하고 어느 상황때 어느 정렬을 사용해야 가장 효율적인지를 파악하면 나중에 정렬 부분에서 훨씬 더 좋은 퍼포먼스를 보여줄 수 있을거라 기대를 하게 되었다.
Ref.
삽입 정렬이란 / https://gmlwjd9405.github.io/2018/05/06/algorithm-insertion-sort.html
삽입 정렬 / https://ko.wikipedia.org/wiki/%EC%82%BD%EC%9E%85_%EC%A0%95%EB%A0%AC
'Algorithm' 카테고리의 다른 글
| [Algorithm] Quick Sort (퀵 정렬) C++ (0) | 2021.08.01 |
|---|---|
| [Algorithm] Merge Sort (합병 정렬) C++ (0) | 2021.07.25 |
| [Algorithm] Bubble Sort (버블 소트) C++ (0) | 2021.07.23 |
| [Algorithm] Selection Sort (선택 정렬) C++ (0) | 2021.07.22 |
| [Algorithm] Asymptotic Notation(점근 표기법) : Big - O Notation(빅 - 오 표기법) (0) | 2021.07.18 |