Modern C++
-
[C++] STL std::vector (벡터) Intro.2021.08.29
-
[C++] C++20 찍먹 Concepts2021.08.28
-
[C++] Template Instantiation (템블릿 인스턴스화)2021.08.27
-
[C++] Smart Pointer Intro (스마트 포인터)2021.08.22
[C++] STL std::vector (벡터) Intro.
STL (Standard Template Library)의 첫 번째 Sequence Container (연속적인 컨테이너)인 std::vector에 대해서 공부를 한다.
std::vector
Vector는 Dynamic Size Array (동적 배열)의 Sequence Constainer (연속적인 컨테이너)이다. 그 뜻은 우리가 일반적으로 특정 Type에 대해서 포인터를 만들고 동적으로 메모리를 할당하는 것과 동일하게 Heap영역에 동적으로 Type에 대한 메모리를 Dynamic 하게 생성해준다.
아래는 일반적으로 포인터를 이용해서 Dynamic Array를 생성한 코드이다.
int main()
{
int* arrayPtr = new int[10];
for(int i = 0; i < 10; ++i)
{
arrayPtr[i] = i;
}
delete[] arrayPtr;
return 0;
}
위 코드와 같이 new키워드를 통해서 integer type의 크기 10자리 메모리 공간을 동적으로 할당하여 그 공간을 arrayPtr이 가리키는 코드이다. 위 코드의 단점은 꼭 해당 메모리 공간을 개발자가 delete를 시켜줘야 한다. 하지만 std::vector는 이러한 공간을 관리를 해준다.
std::vector의 선언은 아래 코드와 같다.
#include <vector>
int main()
{
std::vector<int> v(10);
for(int i = 0; i < 10; ++i)
{
v[i] = i;
}
return 0;
}
std::vector를 이용해서 포인터로 동적 할당한 코드와 동일한 코드를 짜보았다. 먼저 std:vector를 사용하기 위해서는 vector헤더를 포함시켜주어야 한다. 그리고 Angle Bracket ('<', '>') 안에 생성하고자 하는 메모리의 타입을 지정을 해주어야 한다 그리고 괄호 안에 크기를 입력해주면 된다. 위 코드에서는 크기를 주었지만 크기를 따로 주지 않고 메모리를 초기화하는 방법이 존재한다.
#include <vector>
int main()
{
std::vector<int> v{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
return 0;
}
선언과 동시에 원소를 초기화 하는 방법은 위와 같다.
이제 생성된 std::vector의 원소 값을 출력을 해보자 std::vector의 원소 출력은 다양한 방식으로 할 수 있는데 크게 3가지를 소개한다.
#include <vector>
#include <iostream>
int main()
{
std::vector<int> nums(10);
//[] indexing
for (std::size_t idx = 0; idx < nums.size(); ++idx)
{
std::cout << nums[idx] << std::endl;
}
//iterator
for (auto itr = nums.begin(); itr != nums.end(); ++itr)
{
std::cout << (*itr) << std::endl;
}
//ranged for (most optimized)
for (const int& num : nums)
{
std::cout << num << std::endl;
}
}
위 세개의 방법은 모두 동일한 출력을 만들어 낸다.
먼더 [] iundecing은 우리가 평소에 배열의 모든 원소를 출력하고자 할 때 자주 쓰는 방법이다. 두 번째는 vector의 iterator를 사용하는 방법이다. itr의 형은 auto로 자동적으로 위 코드에서는 vector <int>::iterator가 된다. 초기값은 nums의 begin() 메서드를 통해서 nums의 시작점을 가리키고 nums가 마지막일 때까지 출력을 하게 된다. 마지막은 ranged for loop (범위 기반 루프)이다. 쉽게 생각해서 num이라는 레퍼런스에 nums 주고 값을 저장하고 배열 출력에 흑화 된 for loop이라고 생각하면 된다. 레퍼런스가 없어도 무방하지만 레퍼런스가 없다면 nums에 대한 복사가 일어나기 때문에 레퍼런스를 붙여주되 배열의 원소의 조작이 없다면 const를 붙여주는 것이 이상적이다. 또한 auto를 이용하여 Type의 추론을 넣어 작성하는 것이 이상적이다. 해당 방법이 가장 Optimized 된 방법이라 해당 방법을 추천한다.
위 코드에서 사용된 begin(), size(), end()메소드는 vector의 메소드이다. 이외에도 수 많은 메소드들이 있기 때문에 다 설명을 하지않고 cppreference를 참고하기 바란다.
Ref.
'Modern C++' 카테고리의 다른 글
| [C++] C++20 찍먹 Concepts (0) | 2021.08.28 |
|---|---|
| [C++] Class, Aliasing, Variable Template (여러 템플릿들) (0) | 2021.08.27 |
| [C++] Template Instantiation (템블릿 인스턴스화) (0) | 2021.08.27 |
| [C++] Template Type Deduction (템플릿 타입 추론) : Perfect Forwarding (0) | 2021.08.26 |
| [C++] Template Intro. (템플릿) : Function Template (함수 템플릿) (0) | 2021.08.26 |
[C++] C++20 찍먹 Concepts
C++20부터 적용된 기능인 Concept에 대해서 아주아주 간단하게 알아보자. Concept는 Template을 이용할 때 Compile-time에 Template에서 의도치 않는 연산을 방지해주는 기능이다. 아직은 많이 사용되는 기능이 아니라 많이 소극적으로 사용을 하되 표준화과 되면 적극적인 사용을 하라고 권하고 싶다.
Concepts
Concept은 Template에 의도한 연산을 방지해주는 기능이다. 예를 들면 아래와 같은 코드가 있다고 하자.
template <typename T>
T mulTwo(T a, T b)
{
return a + b;
}
위와 같은 template함수가 있다면 Template함수를 만든 개발자는 +연산이 가능한 integer나 double의 연산을 하기 위해 만들었다. 하지만 다른 사람이 이 함수를 보고 std::string객체를 넘겨서 두 문자열이 합쳐지는 기능으로 사용됐다고 생각하면 개발자의 의도가 아닌 다른 방향으로 사용이 되게 된다. 아무리 주석을 이용해서 사용했으면 하는 Data Type을 써놓아도 방지가 어렵기 때문에 뒤에 require 키워드를 통해서 사용 가능한 Type을 적어주고 Compile-time에 검사를 하는 방법으로 해당 문제를 방지할 수 있다.
아래 코드는 concept의 사용법과 Template Function에 require을 통해서 사용 가능한 type을 명시해주는 예이다.
#include <iostream>
#include <concept>
template<typename T>
concept type_that_can_be_used = std::integral<T> || std::floating_point<T>; //integer Type, float Type만 사용이 가능하게 만든 concept
template<typename T>
T mulTwo(T a, T b)
{
return a + b;
}
int main()
{
std::cout << mulTwo(1, 2) << '\n';
std::cout << mulTwo(1.2f, 1.5f) << '\n';
std::cout << mulTwo<std::string>("Hi~", " pretending");
}
위 코드는 concept를 만들어 주었지만 Template Function에서 requires키워드를 통해 concept를 불러오지 않았다. 그렇기 때문에 위 코드는 컴파일이 정상적으로 진행된다.
#include <iostream>
#include <concept>
template<typename T>
concept type_that_can_be_used = std::integral<T> || std::floating_point<T>; //integer Type, float Type만 사용이 가능하게 만든 concept
template<typename T>
T mulTwo(T a, T b) requires type_that_can_be_used<T>
{
return a + b;
}
int main()
{
std::cout << mulTwo(1, 2) << '\n';
std::cout << mulTwo(1.2f, 1.5f) << '\n';
//std::cout << mulTwo<std::string>("Hi~", " pretending"); ERROR
}
위와 같이 requires를 통해 만들어준 concept을 적어주면 Compile-time에 std::string은 ERROR가 나게 해 준다. concet을 선언할 때는 concpet이름과 뒤에 concept 라이브러리에 있는 Sepcifier를 이용해야 하는데 엄청 많다.
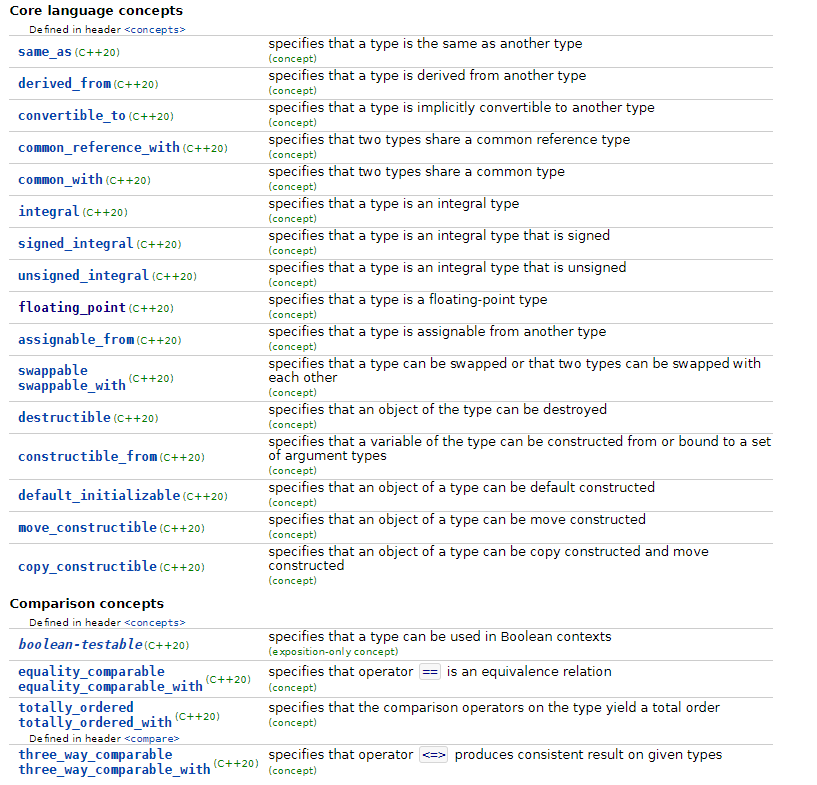
더 많으니 cppreference를 참고하기 바란다.
concept 간단하게 알아보고 자세히 알아보고 싶다면 아래 cppreference를 참고하기 바란다.
Ref.
https://en.cppreference.com/w/cpp/concepts
https://www.youtube.com/watch?v=phZbmGNGqew&list=PLDV-cCQnUlIb2oezNpNTmxiiX_NibMrlO&index=6&t=329s
'Modern C++' 카테고리의 다른 글
| [C++] STL std::vector (벡터) Intro. (0) | 2021.08.29 |
|---|---|
| [C++] Class, Aliasing, Variable Template (여러 템플릿들) (0) | 2021.08.27 |
| [C++] Template Instantiation (템블릿 인스턴스화) (0) | 2021.08.27 |
| [C++] Template Type Deduction (템플릿 타입 추론) : Perfect Forwarding (0) | 2021.08.26 |
| [C++] Template Intro. (템플릿) : Function Template (함수 템플릿) (0) | 2021.08.26 |
[C++] Class, Aliasing, Variable Template (여러 템플릿들)
이번 포스트에서 다룰 내용은 다양한 Template에 대해서 공부한다. 이제까지 배운 Template은 Temlate Function밖에 없었지만 이번에는 다양한 Template에 대한 사용법을 알아본다. 먼저 배울 Template은 아래와 같다.
- Class Template
- Aliasing Temlate
- Variable Template
Class Template (클래스 템플릿)
Class template은 우리가 알게 모르게 사용을 많이 한다. STL(Dtandard Template Library) 자체가 Template으로 구성된 라이브러리이다. Class Template도 Template Function과 동일하게 사용을 하면 된다. 필자는 Template에 대해서 공포감을 느끼기 때문에 충분히 이해가 가능하지만 거부감이 든다. 아래는 Template을 이용해서 push와 pop만 가능한 Data Sturcture의 Stack을 만든 예제이다.
이미 다 공부한 내용이라 코드 첨부로 설명을 마친다.
template<typename T>
class Stack
{
public:
void push(T elem)
{
mVec.emplace_back(std::move(elem));
}
bool pop(T& elem)
{
if (mVec.size() == 0)
return false;
elem = mVec[mVec.size() - 1];
mVec.pop_back();
return true;
}
private:
std::vector<T> mVec;
};
int main()
{
Stack<std::string> stack;
stack.push("jiyong");
stack.push("is");
stack.push("he");
std::string n;
while (stack.pop(n))
{
std::cout << n << '\n';
}
}
Aliasing Template (별명 템플릿?)
Alias는 별명 혹은 별칭이라는 뜻을 가지고 있다. 결국 Aliasing Template은 별명을 가지게 하는 게 Template을 이용해서 별명을 만든다고 생각하면 쉽다.
#include <vector>
#include <array>
template<typename T>
using pretendKeys = std::vector<std::array<T, 64>>;
int main()
{
/*
* alias
* using pretendInt = int;
* using pretendKeys = std::vector<int*_t, 64>;
*/
pretendKeys<float> floatKeys;
//std::vector<std::array<float, 64>> floatKeys
pretendKeys<double> doubleKeys;
//std::vector<std::array<double, 64>> doubleKeys
}
alias을 만드는 법은 using 키워드를 통해 만들 수 있다. C++03에서는 typedef를 사용했지만 C++11에서부터 using을 사용해서 더 직관적이게 "별명"을 붙일 수 있다.
Variable Template (변수 템플릿) C++14
먼저 Variable Template을 설명하기 전에 const와 constexpr에 대해서 짧게 설명한다.
int main()
{
int n = 10;
const int a = 10 + n;
constexpr int b = 11 + n; //ERROR 컴파일 타임에 n이 정해지지 않음.
return 0;
}
const와 constexpr 둘 다 상수를 선언하는 키워드이다. 둘의 차이점은 컴파일 상수이냐 런타임 상수이냐의 차이이다. const는 런타임에 초기값이 정해져 있어야 하고 constexpr는 컴파일 타임에 초기값이 정해져 있어야 한다는 차이점이다.
이제 Variable Template (변수 템플릿)에 대해서 공부를 하자.
변수 템플릿도 별거 없다. C++14부터 지원되는 기능이다. 아래 예제를 보고 충분히 이해할 수 있다.
#include <iostream>
template<typename T>
constexpr T number = T(123.123);
int main()
{
std::cout << number<int>;
return 0;
}
Variable Template으로 number라는 상수를 선언하고 123.123이라는 값으로 초기화를 하였다.
main함수에서 number상수에 Anlge Bracket으로 Type을 int로 명시하여 출력해주면 integer값으로 Casting이 되고 123이 출력이 된다.
Ref.
https://www.youtube.com/watch?v=87nJ-3U4LkA&list=PLDV-cCQnUlIb2oezNpNTmxiiX_NibMrlO&index=5
'Modern C++' 카테고리의 다른 글
| [C++] STL std::vector (벡터) Intro. (0) | 2021.08.29 |
|---|---|
| [C++] C++20 찍먹 Concepts (0) | 2021.08.28 |
| [C++] Template Instantiation (템블릿 인스턴스화) (0) | 2021.08.27 |
| [C++] Template Type Deduction (템플릿 타입 추론) : Perfect Forwarding (0) | 2021.08.26 |
| [C++] Template Intro. (템플릿) : Function Template (함수 템플릿) (0) | 2021.08.26 |
[C++] Template Instantiation (템블릿 인스턴스화)
Template Build (Instantiation)은 C++ 코드를 짤 때 Header와 Cpp파일을 분리해서 코드를 따게 되는데 Template 함수를 Header에 Declaration을 하고 Cpp파일에 Definition을 하고 컴파일을 하면 에러가 뜨고 컴파일이 되지 않는다. 해당 문제가 왜 발생하는지 알아보자.
Template Instantiation (템플릿 인스턴스화)
템플릿 인스턴스화에는 크게 아래 두 가지 종류가 있다.
- Implicit Instantiation (암시적 인스턴스화)
- Explicit Instantiation (명시적 인스턴스화)
Implicit Instantiation (암시적 인스턴스화)는 우리가 Template함수를 정의하고 main함수에서 Angle Bracket으로 차입을 명시해주어 함수를 호출하는 방식을 말한다. 암시적 인스턴스화는 두 가지가 있는데 다 이미 배웠던 내용이다.
코드를 통해서 두 가지 암시적 인스턴스화에 대해서 알아본다.
암시적 인스턴스화는 두 가지가 있다.
- 사용자가 Angle Bracket ('<', '>')에 Type을 명시해주는 방법
- Template Type Deduction (타입 추론)을 이용해 Type을 명시하지 않는 방법
#include <iostream>
template<typename T>
T foo(T a)
{
std:::cout << a << '\n';
}
int main()
{
foo<int>(12); //사용자가 Type을 직점 Angle Bracket에 넣어주는 방법
foo(12); //Template Type Deduction을 이용해 Type을 명시해주지 않는 방법
return 0;
}
Template 함수는 함수를 호출(인스턴스화) 하기 전까지 코드로 존재하다가 인스턴스 화가 되면서 해당 Type혹은 Deduction을 통해서 함수를 만들게 된다.
그렇다면 Header 파일에 Template함수에 대한 Declaration을 작성하고 Cpp 파일에 Definition을 작성하게 되면 정상적으로 코드가 동작하는지 확인해보자.
main.cpp
#include <iostream>
int main()
{
foo<int>(12); //사용자가 Type을 직점 Angle Bracket에 넣어주는 방법
foo(12); //Template Type Deduction을 이용해 Type을 명시해주지 않는 방법
return 0;
}
foo.h
#pragma once
template<typename T>
T foo(T a);
foo.cpp
template<typename T>
T foo(T a)
{
std:::cout << a << '\n';
}
위와 같이 Template 함수의 Declaration를 foo.h에 함수의 Definition을 foo.cpp에 적는다면 컴파일 에러가 나게 된다. 컴파일 에러가 나게 되는 이유는 Template는 함수 자체가 아니고 컴파일러가 Instantiation이 발생하면 코드로 만들어주는 기능을 하게 된다. 여기서 Template을 보고 코드를 만들게 되는데 foo.h에 있는 내용 즉 Declaration만 보고는 어떠한 코드를 만들지를 모르기 때문에 컴파일 에러가 난다.
위 에러를 해결하기 위해서 두 가지 방법을 사용할 수 있는데 코드로 알아본다.
main.cpp
#include <iostream>
int main()
{
foo<int>(12); //사용자가 Type을 직점 Angle Bracket에 넣어주는 방법
foo(12); //Template Type Deduction을 이용해 Type을 명시해주지 않는 방법
return 0;
}
foo.h
#pragma once
template<typename T>
T foo(T a)
{
std:::cout << a << '\n';
}
위와 같이 cpp파일에 Definition을 따로 적지 않고 header 파일에 정의까지 해주는 방법이 있다.
굳이 cpp 파일에 정의를 해서 코드를 만들고 싶다면 cpp 파일 안에 Type Explicit Instantiation을 하면 문제가 해결된다. 이 뜻은 무엇이냐면 cpp 파일 안에 특정 Type에 대한 함수로 컴파일을 해달라고 요청한다고 생각하면 된다. 하지만 이럴 경우 사용하고자 하는 Type에 대해서 모두 Explicit 하게 선언을 해주어야 한다.
main.cpp
#include <iostream>
int main()
{
foo<int>(12); //사용자가 Type을 직점 Angle Bracket에 넣어주는 방법
foo(12); //Template Type Deduction을 이용해 Type을 명시해주지 않는 방법
return 0;
}
foo.h
#pragma once
template<typename T>
T foo(T a);
foo.cpp
template<typename T>
T foo(T a)
{
std:::cout << a << '\n';
}
template int foo<int>(int); //explicit template instatiation
'Modern C++' 카테고리의 다른 글
| [C++] C++20 찍먹 Concepts (0) | 2021.08.28 |
|---|---|
| [C++] Class, Aliasing, Variable Template (여러 템플릿들) (0) | 2021.08.27 |
| [C++] Template Type Deduction (템플릿 타입 추론) : Perfect Forwarding (0) | 2021.08.26 |
| [C++] Template Intro. (템플릿) : Function Template (함수 템플릿) (0) | 2021.08.26 |
| [C++] Weak Pointer (위크 포인터) : Circular Reference (순환 참조) 해결 (0) | 2021.08.25 |
[C++] Template Type Deduction (템플릿 타입 추론) : Perfect Forwarding
Template으로 만들어진 함수를 사용하기 위해서는 함수명 뒤에 Argument Type을 명시를 해주어야 했다. 하지만 Argument Type을 명시하지 않아도 컴파일러가 Argument를 보로 Deduction (추론)을 하여 해당 타입의 함수를 만들어 준다.
Template Type Deduction (템플릿 타입 추론)
Template으로 구선된 함수는 타입을 추론할 수 있다. 아래 코드는 타입이 명시됐을 때와 안 됐을 때의 예를 보여주는 코드이다.
#include <iostream>
template<typename T>
void printVar(T a)
{
std::cout << typeid(a).name() << std::endl;
std::cout << a << std::endl;
}
int main()
{
int a = 100;
printVar<int>(a); //type 명시
printVar(a); //type 미명시
return 0;
}
main함수에서 Type을 명시하여 Template함수를 호출하는 것과 Type을 명시하지 않고 Template함수를 호출하였다. 출력 화면은 아래와 같다.

출력 콘솔에서 확인을 하게 되면 두 호출 모두 int 타입의 함수가 만들어지고 Argument로 넘어간 값도 출력이 잘 되었다. 이와 같이 Template 함수는 Argument를 보고 Type을 Deduction (추론)을 하게 된다. 일만 integer나 string클래스에 대해서는 다 문제없이 잘 작동하는데 Parameter를 Reference로 받거나 R-Value로 받을 경우는 어떻게 되나 궁금할 수 있다.
Template 함수도 일반 함수와 같이 Reference Type 혹은 R-value Reference Type으로 받는 것이 가능하다. 먼저 Reference와 R-Value Reference의 일반 함수를 만들어 보면 아래와 같다.
#include <iostream>
template<typename T>
void printLRef(int& a)
{
std::cout << a << std::endl;
}
void printRRef(int&& a)
{
std::cout << a << std::endl;
}
int main()
{
int a = 100;
printLRef(a);
printRRef(a); //ERROR
return 0;
}
printLRef는 L-Value를 printRRef는 R-Vlaue를 받아주는데 main함수에서 printRRef(a);는 L-Value를 넘겨주기 때문에 컴파일 에러가 난다. 해당 에러를 고쳐주기 위해서는 std::move() 함수를 통해서 R-Vlaue로 변환을 한 후에 Argument로 넘겨줘야 한다.
Template 함수를 이용해 위와 같은 함수를 만든다고 가정을 해보자. Template을 사용하는 이유는 어떠한 Type을 Argument로 주어도 Compile-time에 해당 타입에 맞는 함수를 만들어 줘야 한다. Template 함수에서 Reference를 이용해서 Argument를 넘겨주는 방법은 아래와 같다.
#include <iostream>
template<typename T>
void printVar(T&& a)
{
std::cout << a << std::endl;
}
int main()
{
int a = 100;
printVar(a);
printVar(std::move(a));
return 0;
}
위 코드에서 Template함수의 Parameter는 T&& R-Value를 받게 되어있다. 하지만 main함수에서 L-Value를 Argument로 넘겨주었는데 에러 없이 컴파일이 문제없이 되었다. 이유는 Template에서 T&&는 R-Value Reference가 아니라 Forward Reference라고 부른다. 당연하게 이는 L-Value Reference가 되기도 하고 R-Value Reference가 되기도 한다.
더 자세히 위 내용을 이해하기 위해 Compiler Explorer를 이용해서 어셈블리 코드를 보자. 아래는 위 코드를 어셈블리 코드로 변환시킨 화면이다.
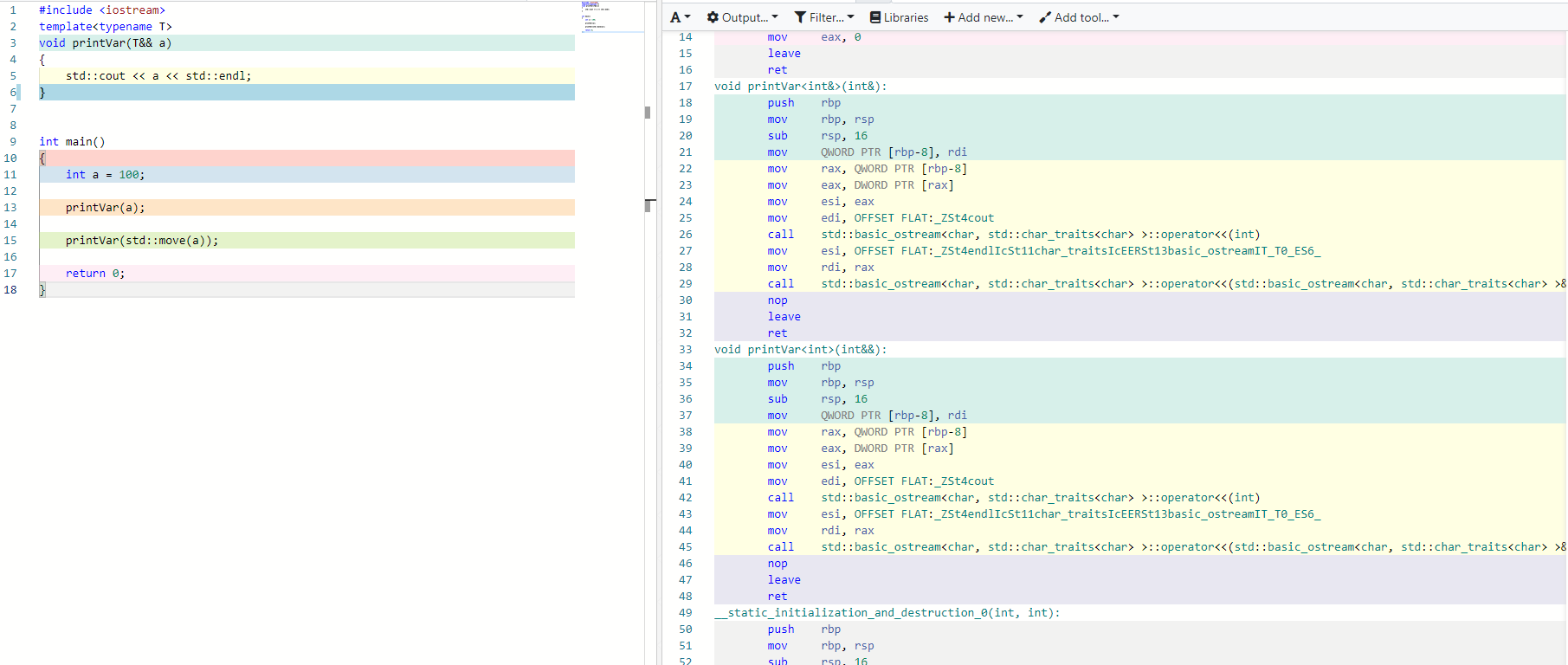
어셈블리 코드를 보게 되면 컴파일러가 함수의 Argument를 보고 맞는 타입의 함수를 만든 것을 확인할 수 있다. L-Value reference를 Argument로 받은 함수는 T가 int&이고 함수의 Parameter는 int&가 된다. R-Value Reference를 Argument로 받은 함수는 T가 int고 Parameter는 int&&가 된다.
R-Value Reference를 사용하는 이유 중 하나는 소유권을 뺏어오는 목적이 있다. 위와 같은 L-Value와 R-Value를 둘 다 넘겨줄 수 있는 Template 함수에서 소유권은 어떻게 취득하는지 알아보자.
Perfect Forwarding
#include <iostream>
template<typename T>
void printVar(T&& a)
{
std::string localVar{ std::forward<T>(a) };
std::cout << localVar << std::endl;
}
int main()
{
std::string str = "pretending";
printVar(str);
printVar(std::move(str));
return 0;
}
main 함수에서 string 객체인 str을 선언하고 template 함수의 Argument로 각각 L-Value Reference와 R-Value Reference로 호출하였다. Template 함수 내에서 localVar이라는 string 객체를 만들어주고 std::forward <T>(a);로 초기화를 해주었는데 이때 std::forward <T>(a);에서 만약 a가 L-Value Reference라면 그대로 L-Vlaue Reference로 놔두게 되고 R-Vlaue Reference라면 그래도 R-Value Reference로 놔두게 된다.
Ref.
https://www.youtube.com/watch?v=Ifo2RtSzqvQ&list=PLDV-cCQnUlIb2oezNpNTmxiiX_NibMrlO&index=3
'Modern C++' 카테고리의 다른 글
| [C++] Class, Aliasing, Variable Template (여러 템플릿들) (0) | 2021.08.27 |
|---|---|
| [C++] Template Instantiation (템블릿 인스턴스화) (0) | 2021.08.27 |
| [C++] Template Intro. (템플릿) : Function Template (함수 템플릿) (0) | 2021.08.26 |
| [C++] Weak Pointer (위크 포인터) : Circular Reference (순환 참조) 해결 (0) | 2021.08.25 |
| [C++] Shared Pointer (쉐어드 포인터) : Circular Reference (순환 참조) (0) | 2021.08.25 |
[C++] Template Intro. (템플릿) : Function Template (함수 템플릿)
학기 중 Template을 이용하여 코드를 짜는 과제가 있었는데 정말 template을 어떻게 사용하는지 모르겠어서 진짜 이상하게 코드를 짰던 기억이 난다. (물론 코드는 짜서 점수는 받았지만...) 지금 다시 template을 제대로 처음부터 다시 공부를 해본다.
Template (템플릿)
Tempalate은 아래와 같이 많은 종류의 Template이 존재한다.
- Function template
- Class Template
- Alias Template
- Variable Template
Template이란 변수의 Type을 정해주지 않고 필요한 Type을 Compile-time에 정의를 해서 사용을 한다. 이러한 특성은 우리가 tyep 때문에 Function Overloading을 해야 할 경우 가장 유용하게 쓰인다.
뭔 뜻인지 이해가 안 될 수 있다. 코드를 통해서 이해를 해보자.
#include <iostream>
int add(int a, int b)
{
return a + b;
}
float add(float a, float b)
{
return a + b;
}
double add(double a, double b)
{
return a + b;
}
int main()
{
std::cout << add(1, 2);
std::cout << add(1.2f, 2.3f);
std::cout << add(1.3, 1.4);
}
위와 같이 두 수를 더해주는 함수를 만드려고 한다. integer타입, float타입 그리고 double타입에 대한 Funciton Overloading에 의해서 3개의 함수가 만들어져야 한다. 하지만 이렇게 타입이 더 늘어나게 되면 많은 함수가 만들어져야 하기 때문에 Template을 이용해서 함수를 만들 수 있다.
Function Template (함수 템플릿)
Template을 이용하여 추상적인 Type을 만들고 컴파일 타임에 각 타입에 맞는 함수가 생성된다고 생각하면 된다.
#include <iostream>
template<typename T>
T add(T a, T b)
{
return a + b;
}
int main()
{
std::cout << add<int>(1, 2);
std::cout << add<float>(1.2f, 2.3f);
std::cout << add<double>(1.3, 1.4);
}위와 같이 template을 이용하여 함수를 만들게 되면 Function Overloading을 이용하여 만든 것보다 더 짧고 명확하게 코드를 짤 수 있다.
Template으로 만들어진 함수는 Compile-time에 정의된다. 이를 확인하기 위해 compiler explorer을 통해서 확인해 보자.
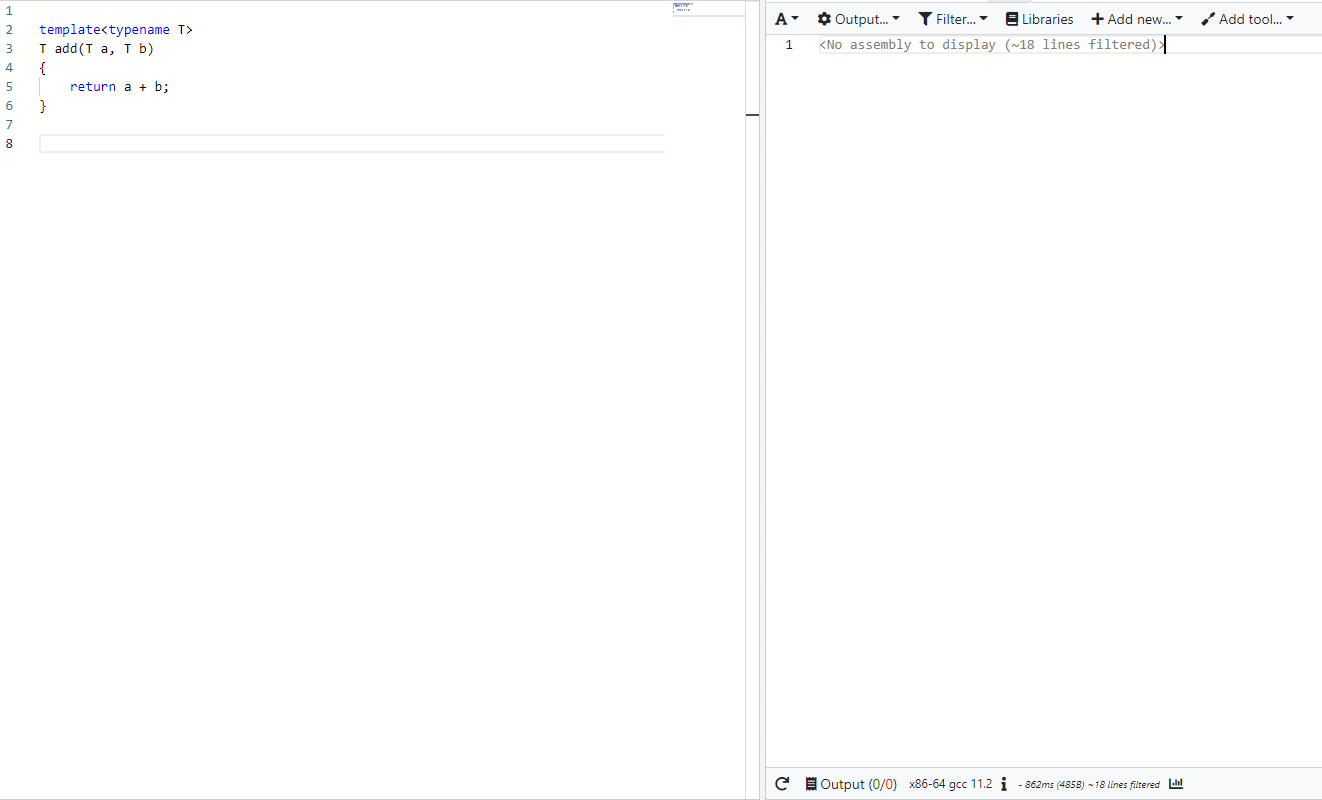
template으로 만들어진 함수만 어셈블리로 변 활했을 경우는 어떤 어셈블리 코드도 만들어지지 않는다.
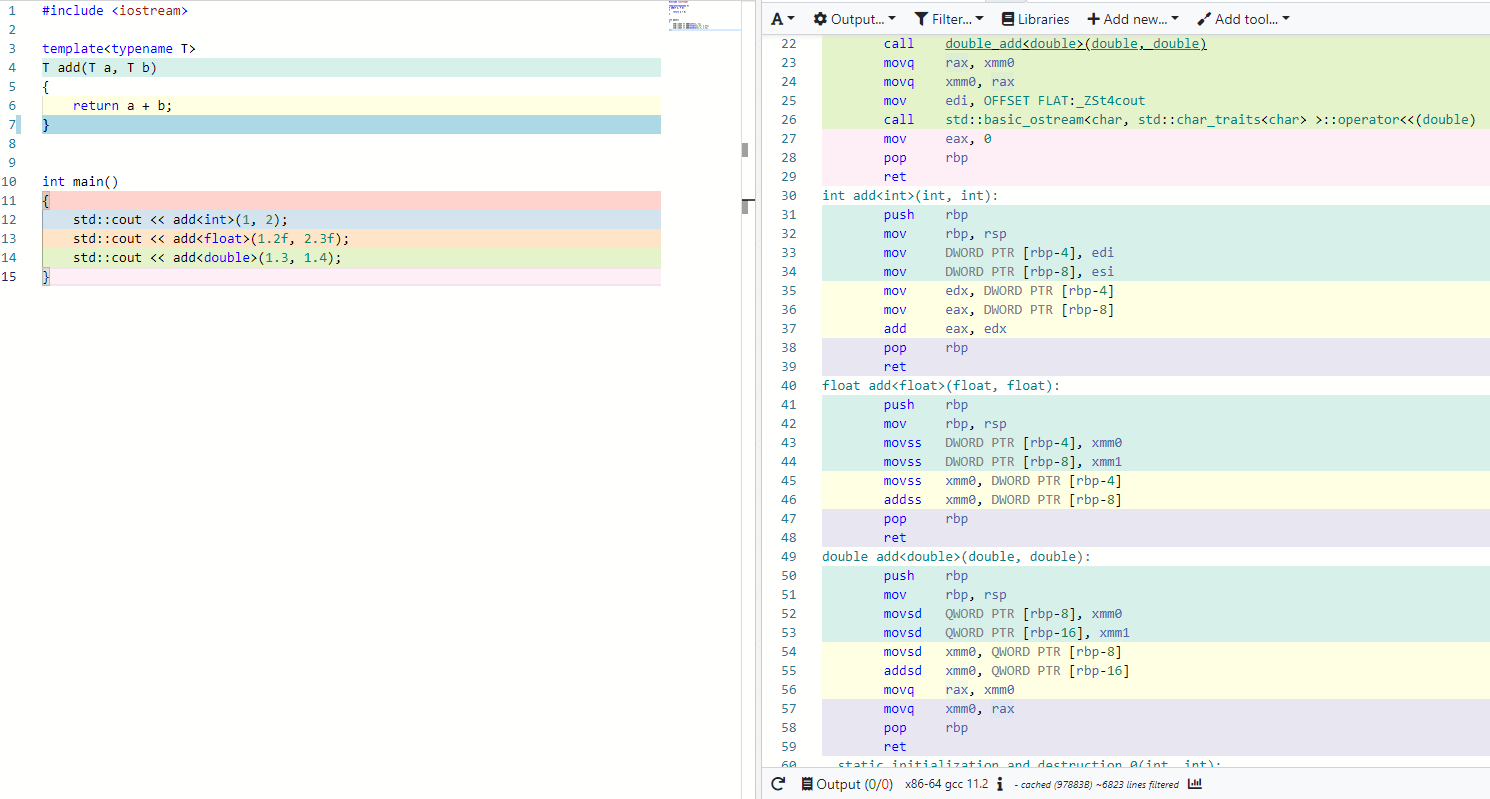
이와 같이 원래는 code로만 존재를 하다가 main함수에서 해당 template function을 사용을 할 때 그 Type에 맞는 함수가 Compile이 되면서 함수가 만들어진다.
여기서 궁금한 것은 모든 자료형에 대해서 적용이 가능한가?
두 개의 const char*형의 + 연산을 한다고 가정을 해보자. 아래 코드와 같이 작성이 가능하다.
#include <iostream>
template<typename T>
T add(T a, T b)
{
return a + b;
}
int main()
{
std::cout << add<const char*>("aaa", "bbb");
}
위와 같은 코드를 컴파일이 안된다. 이유는 const char*형에 대해서 +연산이 정의되어있지 않기 때문이다. Template Function은 모든 것이 만들어져 있는 것이 아니라 넘겨지는 Type에 따라서 그때 Compile이 되게 된다.
이번 포스트는 Template에 대해서 간단하게 알아보았다.
Ref.
'Modern C++' 카테고리의 다른 글
| [C++] Template Instantiation (템블릿 인스턴스화) (0) | 2021.08.27 |
|---|---|
| [C++] Template Type Deduction (템플릿 타입 추론) : Perfect Forwarding (0) | 2021.08.26 |
| [C++] Weak Pointer (위크 포인터) : Circular Reference (순환 참조) 해결 (0) | 2021.08.25 |
| [C++] Shared Pointer (쉐어드 포인터) : Circular Reference (순환 참조) (0) | 2021.08.25 |
| [C++] Smart Pointer (스마트 포인터): Unique Pointer (유니크 포인터) (0) | 2021.08.23 |
[C++] Weak Pointer (위크 포인터) : Circular Reference (순환 참조) 해결
Shared Pointer를 이용하여 Circular Reference를 하여 Memory Leak이 발생할 수 있다고 공부를 했다. Weak Pointer의 개념에 대해서 공부하고 이를 이용하여 Circular Reference문제를 해결해 보자.
Weak Pointer (위크 포인터)
Weak Pointer는 말 그대도 약간 포인터이다. Shared Pointer를 참조하는 용도로 사용을 하게 되고 Weak Pointer가 Shared Pointer를 참조를 하게 되면 Weak Count가 증가하게 된다. Weak Pointer를 이용하여 오브젝트의 리소스를 접근할 수 없다. Weak Pointer를 사용을 하려면 반드시 Shared Pointer형을 반환해 주는 lock() 메서드를 이용하여 Shared Pointer로 변환을 해야 되는데 이때 참조하는 Shared Pointer의 Strong Count가 증가하게 된다는 것을 잊으면 안 된다.
아래는 Weak Pointer가 선언되고 Shared Pointer를 참조하는 코드이다.
#include <iostream>
#include <memory>
class Cat
{
public:
Cat(std::string name) : mName{ name }
{
std::cout << mName << " cat constructor" << std::endl;
}
virtual void speak() const
{
std::cout << "Hi?" << std::endl;
}
~Cat()
{
std::cout << mName << " cat destructor" << std::endl;
}
std::shared_ptr<Cat> mVar;
private:
std::string mName;
};
int main()
{
std::shared_ptr<Cat> kitty = std::make_shared<Cat>("kitty");
std::weak_ptr<Cat> weak_kitty = kitty;
//weak pointer 선언 및 shared pointer kitty참조
std::cout << "count : " << kitty.use_count() << std::endl;
return 0;
}
위 코드를 보면 Shared Pointer kitty를 선언하고 Cat 오브젝트를 생성하였다. 그다음 Weak Pointer를 선언하여 kitty가 가리키고 있는 오브젝트를 참조를 하였다. 그다음 kitty가 가리키고 있는 오브젝트의 count를 출력한 결과 1이 출력이 되었다.
만약 Weak Pointer가 참조하고 있는 오브젝트의 리소스를 사용하고 싶다면 lock() 메서드를 통해 Shared Pointer를 반환받을 수 있다. 아래 코드는 Weak Pointer의 lock() 메서드를 통해 새로운 Shared Pointer를 생성하여 리소스를 사용하는 코드이다.
#include <iostream>
#include <memory>
class Cat
{
public:
Cat(std::string name) : mName{ name }
{
std::cout << mName << " cat constructor" << std::endl;
}
virtual void speak() const
{
std::cout << "Hi?" << std::endl;
}
~Cat()
{
std::cout << mName << " cat destructor" << std::endl;
}
std::shared_ptr<Cat> mVar;
private:
std::string mName;
};
int main()
{
std::shared_ptr<Cat> kitty = std::make_shared<Cat>("kitty");
std::weak_ptr<Cat> weak_kitty = kitty;
if(const auto shared_kitty = weak_kitty.lock())
{
shared_kitty->speak();
}
else
{
std::cout << "pointing nothing\n";
}
return 0;
}
위 코드는 if문 조건문에 const auto shared_kitty에 Weak Pointer weak_kitty의 lock() 메서드를 통하여 Shared Pointer를 반환해주었다. 만약 가리키고 있는 Shared Pointer가 메모리 해제가 된 경우 empty shared_ptr를 반환해준다. 위 경우 weak_kitty가 가리키고 있는 kitty 오브젝트는 마메로 해제가 안되었기 때문에 해당 shared_pointer를 반환한다. if 조건문을 scope로 가지는 shared_kitty가 kitty 오브젝트를 가리키고 있기 때문에 kitty의 count가 2로 증가하게 되고 조건문이 끝나고 다시 1로 감소된다.
그렇다면 아래 코드를 보자.
#include <iostream>
#include <memory>
class Cat
{
public:
Cat(std::string name) : mName{ name }
{
std::cout << mName << " cat constructor" << std::endl;
}
virtual void speak() const
{
std::cout << "Hi?" << std::endl;
}
~Cat()
{
std::cout << mName << " cat destructor" << std::endl;
}
std::shared_ptr<Cat> mVar;
private:
std::string mName;
};
int main()
{
std::weak_ptr<Cat> weak_kitty;
{
std::shared_ptr<Cat> kitty = std::make_shared<Cat>("kitty");
weak_kitty = kitty;
}
if(const auto shared_kitty = weak_kitty.lock())
{
shared_kitty->speak();
}
else
{
std::cout << "pointing nothing\n";
}
return 0;
}
위 코드는 Weak Pointer는 main함수 scope에 선언이 되었고 Shared Pointer인 kitty는 Curly brace scope에 선언이 되었다. 먼저 괄호 안에 선언된 kitty에 Cat 오브젝트를 생성하고 main함수 scope에 있는 weak_kitty를 kitty오브젝트를 참조하게 했다. 괄호를 벗어나고 if문에서 weak_kitty의 lock() 메서드로 Shared Pointer를 반환하려고 했지만 kitty 오브젝트는 이미 괄호 안에서 할당 해제가 되었기 때문에 empty Share Pointer가 반환되어 pointing nothing을 출력하게 된다.
Circular Reference (순환 참조) 해결
#include <iostream>
#include <memory>
class Cat
{
public:
Cat(std::string name) : mName{ name }
{
std::cout << mName << " cat constructor" << std::endl;
}
~Cat()
{
std::cout << mName << " cat destructor" << std::endl;
}
std::shared_ptr<Cat> mVar;
private:
std::string mName;
};
int main()
{
std::shared_ptr<Cat> kitty = std::make_shared<Cat>("kitty");
std::shared_ptr<Cat> nabi = std::make_shared<Cat>("nabi");
kitty->mVar = nabi;
nabi->mVar = kitty;
std::cout << "kitty count : " << kitty.use_count() << std::endl;
std::cout << "nabi count : " << nabi.use_count() << std::endl;
}
저번 포스팅에서 다루었던 오브젝트 내부의 Shared Pointer가 서로 다른 오브젝트를 가리키게 되어 count가 줄지 않아 메모리 해제가 안되었던 문제를 Weak Pointer로 해결할 수 있다. 단순하게 클래스 내부의 Shared Pointer를 Weak Pointer로 교체를 하면 문제는 해결된다.
#include <iostream>
#include <memory>
class Cat
{
public:
Cat(std::string name) : mName{ name }
{
std::cout << mName << " cat constructor" << std::endl;
}
~Cat()
{
std::cout << mName << " cat destructor" << std::endl;
}
std::weak_ptr<Cat> mVar;
private:
std::string mName;
};
int main()
{
std::shared_ptr<Cat> kitty = std::make_shared<Cat>("kitty");
std::shared_ptr<Cat> nabi = std::make_shared<Cat>("nabi");
kitty->mVar = nabi;
nabi->mVar = kitty;
std::cout << "kitty count : " << kitty.use_count() << std::endl;
std::cout << "nabi count : " << nabi.use_count() << std::endl;
}
이렇게 코드를 바꾸게 되면 count는 증가하지 않고 main함수 스코프를 가진 kitty와 nabi가 할당 해제가 되면서 각 오브젝트로 메모리 해제가 된다.
Ref.
'Modern C++' 카테고리의 다른 글
| [C++] Template Type Deduction (템플릿 타입 추론) : Perfect Forwarding (0) | 2021.08.26 |
|---|---|
| [C++] Template Intro. (템플릿) : Function Template (함수 템플릿) (0) | 2021.08.26 |
| [C++] Shared Pointer (쉐어드 포인터) : Circular Reference (순환 참조) (0) | 2021.08.25 |
| [C++] Smart Pointer (스마트 포인터): Unique Pointer (유니크 포인터) (0) | 2021.08.23 |
| [C++] Smart Pointer Intro (스마트 포인터) (0) | 2021.08.22 |
[C++] Shared Pointer (쉐어드 포인터) : Circular Reference (순환 참조)
Unique Pointer에 이어서 Smart Pointer의 한 종류인 Shared Pointer에 대해서 정리한다.
Shared Pointer (쉐어드 포인터)
이름에서도 알 수 있듯이 해당 포인터는 Exclusive Ownership을 가지는 Unique pointer와 다르게 Shared Ownership을 가지게 된다. 그 말은 하나의 오브젝트를 여러 개의 포인터가 가질 수 있다. 하지만 모든 스마트 포인터는 RAII콘셉트를 제공을 해야 한다. Shared Pointer는 여러 개의 포인터가 가리킴에도 불구하고 어떻게 오브젝트의 메모리 할당을 해제시키는지 알아보자.
아래 코드는 쉐어드 포인터를 선언하는 코드이다.
class Dog
{
public:
Dog() : mAge { 0 }
{
std::cout << "dog Constructor" << std::endl;
}
~Dog()
{
std::cout << "Dog destructor" << std::endl;
}
private:
int mAge;
}
int main()
{
std::shared_ptr<Dog> dogPtr = std::make_shared<Dog>();
}위 코드에서 dogPtr이라는 쉐어드 포인터를 생성하고 Dog객체를 할당하였다. 위 과정에서 해당 포인터의 scope단위는 main함수이고 객체가 생성이 되면서 Constructor를 부르게 되고 main함수가 종료되면서 자동적으로 Destrucotr를 호출하게 된다.
하지만 쉐어드 포인터의 특성으로 다른 쉐어드 포인터가 하나의 오브젝트를 가리킬 수 있다. 아래의 코드는 여러 개의 쉐어드 포인터가 하나의 오브젝트를 가리키는 예이다.
int main()
{
std::shared_ptr<Dog> dogPtr = std::make_shared<Dog>();
std::shared_ptr<Dog> dogPtr1 = dogPtr;
}위와 같은 경우 Unique Pointer와 다르게 하나의 오브젝트를 두 개의 포인터가 가리키게 된다. 만약에 여기서 끝이라면 일반 포인터와 다를 바가 없다. 일반 포인터와 다른 점은 가리키는 메모리 공간에 몇 개의 포인터가 오브젝트를 가리키는지 Count를 한다. Count 중에서도 Strong Count와 Weak Count가 있는데 쉐어드 포인터가 가리키게 되면 Strong Count가 올라가고 오브젝트는 Strong Count가 0일 때 메모리를 해제를 결정하게 된다. Weak Pointer가 가리키게 되는 경우는 Weak Count가 올라가지만 메모리를 해제하기 위해서 참고되지는 않는다.
Shared Pointer은 개발자가 Rsource의 Life Cycle을 고려하지 않고(메모리 해제를 고려하지 않고) 한 오브젝트의 Ownership을 여러 Scope에서 공유가 가능하게 만들어준다.
하지만 이러한 특성 때문에 의도치 않은 Memory Leak이 일어날 수 있다.
아래 코드는 Shared Pointer 사용함에 있어서 Memory Leak이 일어나는 가장 쉬운 예이다.
#include <iostream>
#include <memory>
class Cat
{
public:
Cat(std::string name) : mName{ name }
{
std::cout << mName << " cat constructor" << std::endl;
}
~Cat()
{
std::cout << mName << " cat destructor" << std::endl;
}
std::shared_ptr<Cat> mVar;
private:
std::string mName;
};
int main()
{
std::shared_ptr<Cat> kitty = std::make_shared<Cat>("kitty");
kitty->mVar = kitty;
std::cout << kitty.use_count() << std::endl;
}먼저 클래스 내에 Shared Pointer mVar를 추가로 생성하였다. main함수에서 Shared Pointer kitty를 선언하고 오브젝트를 생성하고 오브젝트 내의 Shared Pointer mVar를 오브젝트 자신인 kitty를 가리키게 만들었다. 그다음 kitty 오브젝트의 Strong Count를 확인하기 위해 use_count()를 이용해 출력을 한 결과 2가 출력이 된다. 이 경우 Memory Leak이 발생하게 되는데 아래 그림을 통해 알아보자.
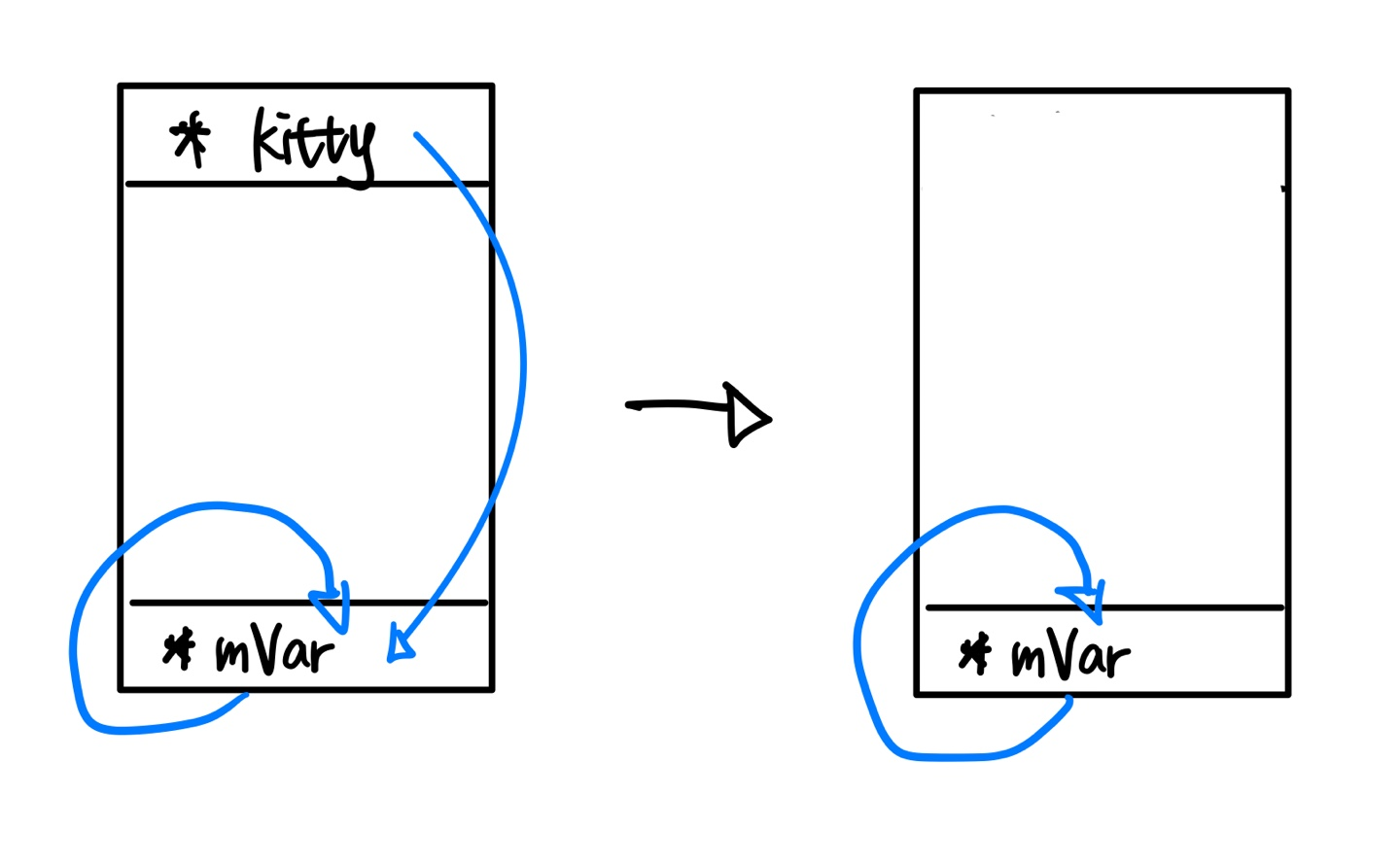
Shared Pointer인 kitty는 main함수 scope가 종료됨에 따라 메모리 해제가 된다. kitty가 사라지고 오브젝트의 Count가 2에서 1로 줄게 된다. Shared Pointer가 해제되고 오브젝트 또한 자동으로 해제되는 것을 기대했지만 오브젝트 내부의 Shared Pointer가 오브젝트를 아직 가리키고 있기 때문에 main함수가 종료됐음에도 불구하고 메모리 해제가 안되어 Memory Leak이 일어난 경우이다.
위 예는 Memory Leak이 일어날 수 있다는 것을 보여주기 위한 예로 실제 많이 발생되지 않는다. 실제로 자주 발생되는 Memory Leak에 대한 코드는 아래와 같다.
Circular Reference (순환 참조)
#include <iostream>
#include <memory>
class Cat
{
public:
Cat(std::string name) : mName{ name }
{
std::cout << mName << " cat constructor" << std::endl;
}
~Cat()
{
std::cout << mName << " cat destructor" << std::endl;
}
std::shared_ptr<Cat> mVar;
private:
std::string mName;
};
int main()
{
std::shared_ptr<Cat> kitty = std::make_shared<Cat>("kitty");
std::shared_ptr<Cat> nabi = std::make_shared<Cat>("nabi");
kitty->mVar = nabi;
nabi->mVar = kitty;
std::cout << "kitty count : " << kitty.use_count() << std::endl;
std::cout << "nabi count : " << nabi.use_count() << std::endl;
}

순환 참조란 위 코드와 그림처럼 클래스 내부에서 Shared Pointer로 다른 클래스가 서로 가리키는 것을 의미한다. kitty 오브젝트와 nabi 오브젝트가 Shared Pointer kitty와 nabi에 의해서 가리키게 되고 내부의 mVar Shared Pointer가 서로의 오브젝트를 가리키게 되면 Shared Pointer가 main함수에서 메모리 해제가 되어도 각 오브젝트의 Count는 1로 메모리 해제가 안 되는 것을 말한다.
위와 같은 Memory Leak을 해결하기 위해 Weak_ptr을 이용하여 Circular Reference를 구현할 수 있다. 다음 포스팅은 Weak_Ptr에 대해서 공부할 예정이다.
Ref.
https://www.youtube.com/watch?v=tg34hwP0P0M&list=PLDV-cCQnUlIbOBiPvBaRPezOLArubgZbQ&index=4
'Modern C++' 카테고리의 다른 글
| [C++] Template Intro. (템플릿) : Function Template (함수 템플릿) (0) | 2021.08.26 |
|---|---|
| [C++] Weak Pointer (위크 포인터) : Circular Reference (순환 참조) 해결 (0) | 2021.08.25 |
| [C++] Smart Pointer (스마트 포인터): Unique Pointer (유니크 포인터) (0) | 2021.08.23 |
| [C++] Smart Pointer Intro (스마트 포인터) (0) | 2021.08.22 |
| [C++] Object Slicing (오브젝트 슬라이싱) (0) | 2021.08.22 |
[C++] Smart Pointer (스마트 포인터): Unique Pointer (유니크 포인터)
Smart Pointer에서 간단하게 Smart Pointer에 대해서 알아보았다. 이번에는 스마트 포인터의 한 종류인 Unique Pointer (유니크 포인터)에 대해서 공부한다.
Unique Pointer (유니크 포인터)
유니크 포인터에 대해서 공부하기 전에 유니크 포인터의 Exclusive Ownership이 뭔지 얘기하고 시작한다.
Exclusive Ownership (소유권 독점)
소유권 독점이란 하나의 Object에 단 하나의 Pointer만 가리킬 수 있다는 것이다. 말 그래로 소유권을 독점한다라는 뜻이다. 일반적인 포인터를 사용하게 되면 한 Object당 여러 개의 포인터가 가리킬 수 있는데 Exclusive Ownership은 아니다.
아래
코드는 하나의 객체에 다수의 포인터가 가리킬 경우 생길 수 있는 문제 중 하나이다.
#include <iostream>
class Cat
{
public:
Cat() : mAge{ 0 }
{
std::cout << "cat constructor" << std::endl;
}
~Cat()
{
std::cout << "cat destructor" << std::endl;
}
private:
int mAge;
};
void memoryDealloc(Cat* dealloc)
{
delete dealloc;
}
int main()
{
Cat* choco = new Cat();
memoryDealloc(choco);
delete choco;
}choco객체를 동적으로 선언을 해주고 메모리를 해제해주는 memoeyDealloc함수를 만들어 delete 해준다. 이 과정에서 main함수에서 실수로 또 delete를 해주게 된다면 한 메모리 공간에 대해서 delete를 두 번 해주는 상황이 발생한다.
이러한 문제를 방지하기 위해서 스마트 포인터를 사용하면 된다.
int main()
{
std::unique_ptr<Cat> catPtr = std::make_unique<Cat>();
std::unique_ptr<Cat> catPtr1 = catPtr; //ERROR
}main함수를 스마트 포인터를 이용하여 다시 고쳐 쓰면 위와 같은데 위 코드에서 스마트 포인터 catPtr과 catPtr1이 선언이 되고 catPtr1는 catPtr이 가리키고 있는 객체의 주소 값을 복사해온다. 하지만 Exclusive Ownership특성 때문에 하나의 객체를 여러 개의 포인터가 가리킬 수 없기 때문에 에러가 난다. 하지만 catPtr1에 해당 객체의 주소 값을 저장하고 싶다면 객체의 소유권을 뺏어오면 된다.
int main()
{
std::unique_ptr<Cat> catPtr = std::make_unique<Cat>();
std::unique_ptr<Cat> catPtr1 = std::move(catPtr);
}위와 같이 dogPtr을 R-Value로 바꾸고 dogPtr1에 소유권을 이전하면 문제가 생기지 않는다.
스마트 포인터 사용 예
Animal Class와 Zoo Class를 추가로 만든다. 그다음 막 개장한 동물원이라서 동물원 안에 동물이 하나밖에 없는 상황이라고 가정을 하면 Zoo Class에 멤버 변수로 Animal 객체 하나만 가지게 된다. 원래 스마트 포인터를 사용하지 않았다면 Rule og Three에 의해서 Destructor, Copy / Move Constructor와 Copy / Move Assignment를 만들어줘야 하지만 스마트 포인터를 이용하면 알아서 scope 단위에서 메모리를 해제해주고 Copy Constructor와 Assignment는 애초에 스마트 포인터가 copy가 안되기 때문에 만들어 주지 않아도 되고 Mov Constructor와 Assignment는 컴파일러가 만들어 주는 함수로 커버가 가능하기 때문에 스마트 포인터를 사용하게 되면 일반 멤버 변수처럼 클래스를 구성해도 무방하다.
'Modern C++' 카테고리의 다른 글
| [C++] Weak Pointer (위크 포인터) : Circular Reference (순환 참조) 해결 (0) | 2021.08.25 |
|---|---|
| [C++] Shared Pointer (쉐어드 포인터) : Circular Reference (순환 참조) (0) | 2021.08.25 |
| [C++] Smart Pointer Intro (스마트 포인터) (0) | 2021.08.22 |
| [C++] Object Slicing (오브젝트 슬라이싱) (0) | 2021.08.22 |
| [C++] Virtual Inheritance (가상 상속) : Diamond Problem (다중 상속 문제) 해결 (0) | 2021.08.21 |
[C++] Smart Pointer Intro (스마트 포인터)
우리는 동적 할당을 Type* ptr = new Type;과 같이 선언하였다. 동적 할당을 할 때 가장 신경 써야 할 부분은 바로 Memory Leak (메모리 누수)이다. 왜냐하면 동적으로 할당된 메모리는 delete키워드를 통해 해제시켜줘야 한다는 단점이 있기 때문이고 우리는 delete를 까먹게 되는 경우가 많다. 이를 해소하기 위해 C++11부터 Smart Pointer을 이용하여 자동적으로 메모리 해제를 해주는 기능이 나왔다.
C++ 에는 RAII (Resouce Acquisition Is Initialization)이 있다. RAII가 생긴 이유는 타 언어들과 다르게 GC (garbage collector)가 존재하지 않기 때문이다 (있기는 하나 사용을 안 한다). 우리가 결국 원하는 건 메모리 누수가 나지 않는 것인데 RAII를 통하여 얻을 수 있다. 결국 RAII란 자원의 안전한 사용을 위해서 scpoe가 끝나면 메모리 해제를 해주는 기법이다.
Smart Pointer (스마트 포인터)
Memory Leak은 정말 짜증 나는 경우이다. 아무 생각 없이 동적 할당을 난발하면 메모리 릭이 발생하는데 나중에 어디서 메모리 릭이 발생하는 건지 찾고 수정하는 데에 시간이 오래 걸린다. 이를 해소하기 위해 Smart Pointer가 등장했다.
Smart Pointer를 선언하는 방법은 아래 코드와 같다.
#include <iostream>
#include <memory>
class Dog
{
public:
Dog(int age) : mAge{ age }
{
std::cout << "Dog constructor" << std::endl;
}
~Dog()
{
std::cout << "Dog destructor" << std::endl;
}
private:
int mAge;
};
int main()
{
std::unique_ptr<Dog> dogPtr = std::make_unique<Dog>(9);
return 0;
}스마트 포인터를 사용하기 위해서는 <memory> 헤더를 include를 시켜주어야 한다. 그다음 main함수 첫 번째 줄과 같이 선언해주면 된다. 위 코드를 돌려보면 자동으로 Comstructor와 Destructor가 불리는 것을 확인할 수 있다.
스마트 포인터는 scope단위로 scope가 끝나면 메모리를 자동으로 해제해준다.
Into이기 때문에 간단하게 설명하고 다른 포스트에서 더 자세하게 다룬다.
Ref.
'Modern C++' 카테고리의 다른 글
| [C++] Shared Pointer (쉐어드 포인터) : Circular Reference (순환 참조) (0) | 2021.08.25 |
|---|---|
| [C++] Smart Pointer (스마트 포인터): Unique Pointer (유니크 포인터) (0) | 2021.08.23 |
| [C++] Object Slicing (오브젝트 슬라이싱) (0) | 2021.08.22 |
| [C++] Virtual Inheritance (가상 상속) : Diamond Problem (다중 상속 문제) 해결 (0) | 2021.08.21 |
| [C++] Multiple Inheritance (다중 상속) (0) | 2021.08.21 |