분류 전체보기
-
[C++] Member Initializer List (멤버 초기화 리스트)2021.08.18
-
[C++] OOP Intro. 객체지향프로그래밍2021.08.16
-
[C C++] String 클래스 : 기본과 메소드2021.08.11
-
[Algorithm] Shell Sort (쉘 정렬) C++2021.08.08
-
[Algorithm] Quick Sort (퀵 정렬) C++2021.08.01
-
[백준] 1978번 : 소수 찾기 C++2021.07.26
-
[Algorithm] Merge Sort (합병 정렬) C++2021.07.25
[C++] Member Initializer List (멤버 초기화 리스트)
Member Initializer List (멤버 초기화 리스트)를 알아보기 전 먼저 Class의 Constructor (생성자), Destructor (소멸자)에 대해서 얘기해보자.
Class Dog
{
public:
Dog()
{
//std::cout << "Constructor" << std::endl;
}
~Dog()
{
//std::cout << "Destructor" << std::endl;
}
private:
};Dog라는 Class를 생성했다. 위와 같이 클래스의 이름과 멤버 함수의 이름이 동일한 것을 볼 수 있다. Constructor는 클래스의 이름을 함수 이름으로 정의해주면 되고 Destructor의 경우 '~'를 붙여 정의해주면 된다.
Member Initializer List
먼저 멤버 초기화 리스트를 이용하지 않고 클래스를 구성해보면 아래와 같다.
Class Dog
{
public:
Dog(int age)
{
mAge = age;
}
~Dog()
{
//std::cout << "Destructor" << std::endl;
}
private:
int mAge;
};필자도 원래 항상 이런 식으로 코드를 짜 왔다. 멤버 초기화 리스트는 기존 함수명 괄호 뒤에 세미콜론 :으로 표기한다. 그다음 초기화하고자 하는 변수들을 쉼표로 구분하고 괄호를 이용하여 초기화를 진행한다.
Class Dog
{
public:
Dog(int age) : mAge(age) {};
~Dog()
{
//std::cout << "Destructor" << std::endl;
}
private:
int mAge;
};멤버 초기화 리스트를 하면 코드가 간략해지는 것 의외의 차이점을 못 찾을 수 있지만 아래의 예시를 보면 왜 멤버 초기화 리스트를 사용하는지 알 수 있다.
#include <iostream>
class Dog
{
public:
Dog() : mAge{ 1 } {};
Dog(int age) : mAge{ age } {};
private:
int mAge;
};
class Zoo
{
public:
//Zoo(int dogAge) : mong(Dog(dogAge)) {};
Zoo(int dogAge)
{
mong = Dog(dogAge);
}
private:
Dog mong;
};
int main()
{
Zoo cppZoo(5);
return 0;
}Zoo라는 클래스를 추가로 생성하여 Zoo클래스에 Dog객체가 생성되도록 만들었다. Zoo의 생성자를 보게 되면 주석 처리된 코드는 Member Initializer List를 이용하여 객체의 생성자를 호출하고 주석이 아닌 Zoo생성자는 일반적으로 대입 연산자를 통해 Zoo클래스의 mong객체를 초기화한다.
위 코드를 어셈블리어로 확인을 하게 되면 둘의 차이를 명백하게 확인할 수 있다.
*참고로 필자는 아직 어셈블리어를 이해하지 못하고 어셈블리 코드를 확인하기 위해 Compiler explorer를 이용했다.

대입 연산자를 통해 mong객체를 초기화하는 코드를 어셈블리어 변환한 모습이다. 우측 어셈블리 코드를 확인해 보면 Zoo::Zoo(int)에 생성자 코드를 보게 되면 먼저 Dog::Dog()인 기본 Dog생성자가 1번 호출이 되고 Dog::Dog(int) 생성자가 한번 더 호출이 되게 된다. 이 뜻은 먼저 임시 객체가 생성이 되고 그 객체에 dogAge의 값으로 초기화가 되 후에 mong객체에 대입 (mov키워드) 이 되는 방식이다. 하지만 대입 초기화 연산자를 이용할 경우는 아래와 같다.

똑같이 우측 어셈블리 코드를 보면 Zoo::Zoo(int)에서 Dog::Dog(int) 생성자가 한번 호출이 되고 그다음 mov키워드가 없는 것을 확인할 수 있다. 이러한 이유 때문에 메모리 관점에서 효율적인 코드를 짜기 위해서 Member initializer list를 사용하는 것이다.
'Modern C++' 카테고리의 다른 글
| [C C++] Overloading (오버 로딩) (0) | 2021.08.19 |
|---|---|
| [C++] Copy / Move Constructor & Assignment (복사, 이동 생성자와 대입 연산자) (0) | 2021.08.19 |
| [C C++] Static Member Function & Static Member Variable (정적 멤버 함수 및 변수) (0) | 2021.08.16 |
| [C++] Memory Alignment (메모리 얼라인먼트) & Object In Memory (객체생성) (1) | 2021.08.16 |
| [C++] OOP Intro. 객체지향프로그래밍 (0) | 2021.08.16 |
[C C++] Static Member Function & Static Member Variable (정적 멤버 함수 및 변수)
본 포스팅에서 다룰 내용은 static member function과 static member variable이다. 정적 멤버 함수와 정적 멤버 변수이다. 여기서 얘기하는 static은 static link와 별개의 내용이다.
Static Member Function
static member variable은 정적 멤버 변수이다. 정적 멤버 함수란 오브젝트가 없이도 호출이 가능한 함수이다. 일반 멤버 함수의 경우는 오브젝트를 생성 후 해당 오브젝트가 가지고 있는 주소 값에 의존하여 멤버 함수를 호출하는 방식이다. 하지만 static member function은 아니다.
#include <iostream>
class Dog
{
public:
void spaek()
{
std::cout << "woof" << '\n';
}
static void staticSpeak()
{
std::cout << "WOOF!" << '\n';
//std::cout << mAge << '\n'; 불가능!
//spaek(); 불가능!
}
private:
int mAge;
};
int main()
{
Dog choco;
choco.spaek();
Dog::staticSpeak(); //객체
choco.staticSpeak(); //오브젝트의 멤버 함수이기 때문에 call가능
}위 코드에서 Dog라는 클래스에 static member function인 staticSpeak() 함수가 존재한다. 해당 함수는 main함수에서 객체를 생성하지 않고 바로 호출이 가능하다. Dog::staticSpeak()와 같은 형식으로 호출이 가능하다. 여기서 추가적으로 staticSpeak()는 클래스의 멤버 함수이기도 하기 때문에 오브젝트를 이용하여 호출 또한 가능하다. choco.staticSpeak();
static member function의 특징으론 해당 함수는 객체의 주소 값을 가지고 있지 않기 때문에 static member function내에서 멤버 변수 혹은 멤버 함수를 호출하는 것이 불가능하다. 왜냐하면 기본적으로 멤버 변수와 멤버 함수는 this초인터를 이용하여 호출이 진행이 되는데 위에 말했다시피 static member function은 해당 주소 값을 가지고 있지 않게 때문이다.
Static Member Variable
static member variable은 정적 멤버 변수이다. 해당 변수는 오브젝트 안에 존재하지 않고 static 메모리 영역에 존재하게 된다. 그 뜻은 하나의 변수를 공유하게 된다는 뜻이다.
#include <iostream>
class Dog
{
public:
static int count;
void spaek()
{
++count;
std::cout << "woof" << '\n';
std::cout << "count : " << count << '\n';
}
private:
int mAge;
};
int Dog::count = 0;
int main()
{
Dog choco;
Dog mong;
choco.spaek();
mong.spaek();
}
클래스를 먼저 보면 static int count static member variable이 public에 선언이 되어있다. static member variable은 프로그램이 실행되기 전에 초기화가 이루어져야 한다. main함수에서 두 객체 choco와 mong의 멤버 함수 speak() 호출을 통해 count를 증가시키고 count를 출력한 결과 mong.spaek()에서 count가 2가 된 것을 확인할 수 있었다. 그 이유는 아까 설명한 대로 static 메모리에 저장이 되어 객체 간 하나의 변수를 공유하기 때문이다.
위 코드에서 문제가 될 수 있는 점이 있다. 바로 static member variable이 public에 선언이 되었기 때문에 객체를 이용해서 해당 변수를 manipulate 할 수 있다는 점이 문제가 될 수 있다. 이 점을 해결하기 위해 private에 옮겨 문제를 해결하는 방법이 있지만 더 나은 해결 방안은 현재 코드에서 해당 변수를 speak() 멤버 함수에서만 사용이 되기 때문에 speak() 멤버 함수 안에 선언하는 방법 또한 안전한 방법이다.
#include <iostream>
class Dog
{
public:
void spaek()
{
static int count = 0; //컴파일할때 한번 선언됨.
++count;
std::cout << "woof" << '\n';
std::cout << "count : " << count << '\n';
}
private:
int mAge;
};
int main()
{
Dog choco;
Dog mong;
choco.spaek();
mong.spaek();
}처음에 speak() 안에 선언하면 선언할떄마다 해당 정적 멤버 변수가 새로 선언이 되는 것이 아닌가라는 생각을 하게 되었는데 잘 생각해보니 해당 변수는 컴파일 타임에 선언이 되기 때문에 런타임에는 해당 선언을 무시하게 된다.
Ref.
https://www.youtube.com/watch?v=oD6fKjyX5to&t=242s
'Modern C++' 카테고리의 다른 글
| [C++] Copy / Move Constructor & Assignment (복사, 이동 생성자와 대입 연산자) (0) | 2021.08.19 |
|---|---|
| [C++] Member Initializer List (멤버 초기화 리스트) (0) | 2021.08.18 |
| [C++] Memory Alignment (메모리 얼라인먼트) & Object In Memory (객체생성) (1) | 2021.08.16 |
| [C++] OOP Intro. 객체지향프로그래밍 (0) | 2021.08.16 |
| [C C++] String 클래스 : 기본과 메소드 (0) | 2021.08.11 |
[C++] Memory Alignment (메모리 얼라인먼트) & Object In Memory (객체생성)
C++ 에는 OOP 패러다임을 적용한 언어이기 때문에 클래스가 존재한다. 본 포스팅은 데이터 얼라인먼트에 대해서 얘기해본다.
먼저 객체를 생성하는 방법은 크게 3가지이다. stack메모리에 객체를 생성하는 방법, heap메모리에 동적으로 생성하는 방법과 static 하게 객체를 생성하는 방법이 있다.
#include <iostream>
class Dog
{
public:
void speak()
{
std::cout << "woof" << '\n';
}
private:
int i4a;
};
Dog staticDog; //static
int main()
{
Dog stackDog; //stack
Dog* heapDog = new Dog; //heap
delete heapDog;
return 0;
}위 코드 main함수를 보게 되면 Dog stackDog가 있다. 해당 객체는 stack영역에 저장이 된다. 다음은 Dog* heapDog는 포인터이다. stack영역에 포인터를 생성하고 heap영역에 객체를 생성한 뒤 포인터가 heap영역의 객체를 가리키는 식으로 메모리가 할당이 된다. 마지막으로 Dog staticDog는 static메모리 공간에 할당이 된다.

이어서 클래스 혹은 구조체의 Memory Alignment에 대해서 설명한다.
Memory Alignment는 메모리가 할당이 어떤 식으로 할당이 되는지에 대한 룰이다. 구조체의 멤버 변수들의 자료형의 크기에 따라 메모리를 할당을 어떻게 해줄까에 대한 얘기이다. 예를 들어서 얘기해보자.
Case 1
class Dog
{
public:
void speak()
{
std::cout << "woof" << '\n';
}
private:
double d8;
int i4a;
int i4b;
};main함수에서 sizeof() 연산자로 해당 클래스의 크기를 출력을 해본 결과 16바이트의 크기를 가지고 있다. 이는 자명하다. 간단하게 메모리에 대한 그림으로 나타내면 아래와 같다.

*char형 자료현은 1바이트, int 자료형 4바이트, double자료형은 8바이트로 가정한다. 이는 환경마다 다르기 때문이다.
double은 8바이트 두 개의 int는 8바이트 이기 때문에 더하면 16바이트라는 답을 쉽게 얻을 수 있다.
Case 2
class Dog
{
public:
void speak()
{
std::cout << "woof" << '\n';
}
private:
int i4a;
double d8;
int i4b;
};이번에는 double형 d8을 int형 멤버 변수 사이에 위치하였다. 해당 케이스도 main함수에서 sizeof() 연산자를 통해 크기를 출력해본 결과 24바이트로 출력이 됐다. 왜 그런 걸까?
이는 Memory Alignment의 두 가지 특징 때문에 일어난 일이다.
Memory Alignment의 두 가지 특징
- 멤버 변수는 해당 변수의 자료형 크기의 배수 위치에서 시작해야 된다.
- 오브젝트의 전체 사이즈는 가장 큰 멤버 변수의 크기의 배수에서 끝나야 한다.
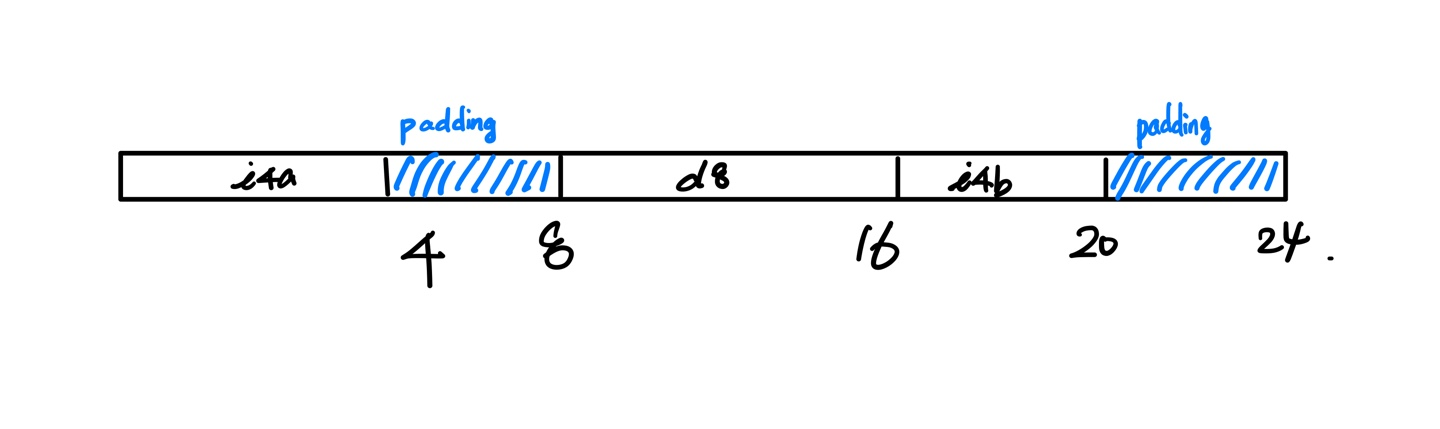
int형 멤버 변수 i4a는 정상적으로 4바이트 공간을 할당을 받았다. 그다음 멤버 변수인 d8을 할당하려고 했으나 할당하려는 위치가 double형 멤버 변수의 크기인 8의 배수가 아니기 때문에 자동적으로 Memory Padding이 일어나 4바이트를 placehold (빈 공간) 채워준다. 이제 시작 위지 차 8이기 때문에 정상적으로 d8을 할당하였다. 그다음 16바이트 위치는 i4b의 자료형이 int이기 때문에 4의 배수가 성립이 되어 할당을 해준다. 마지막으로 Memory Alignment의 특징인 오브젝트의 전체 사이즈는 가장 큰 멤버 변수의 크기의 배수로 끝나야 한다는 특징이 있기 때문에 가장 큰 멤버 변수는 double형 즉, 8바이트의 배수로 끝나야 하기 때문에 4바이트를 Padding을 더해주어 마지막으로 24바이트로 끝이 난다는 것을 확인할 수 있다.
Cache line
나중에 다른 포스트에서 자세히 다룰 예정이지만 간단히 공부한 내용을 정리해보자면 프로세서는 정보를 처리할 때 cache line을 이용하여 데이터를 끊어서 처리를 하게 되는데 이 끊어지는 크기가 대체적으로 64바이트라고 한다. 그렇다면 아래 코드를 보자.
class Dog
{
public:
void speak()
{
std::cout << "woof" << '\n';
}
private:
int i4a;
double d8;
int i4b;
};
int main()
{
Dog DogArr[10];
return 0;
}크기가 10인 Dog 객체 배열을 만들면 메모리는 아래와 같이 할당될 것이다.

배열에 담긴 10개의 객체들이 연이어 메모리를 할당받게 되지만 cache line이 데이터를 처리하기 위해선 cache line으로 잘라서 처리를 하게 된다. 이 과정에서 3번째 객체는 사진과 같이 2조각으로 나누어 처리를 하게 된다. 이런 형상은 False Sharing이라고 한다. 이러한 불상사를 예방하기 위해 이와 같이 코드를 짤 수 있다.
class alignas(32) Dog
{
public:
void speak()
{
std::cout << "woof" << '\n';
}
private:
int i4a;
double d8;
int i4b;
};
int main()
{
Dog DogArr[10];
return 0;
}alignas(32)를 축가 해줌으로 각 객체의 메모리가 32바이트로 할당이 되고 원래 24바이트에서 추가된 8바이트는 Padding으로 채워지게 된다.
Ref.
https://nocodeprogram.com/lecture/1/94892/
'Modern C++' 카테고리의 다른 글
| [C++] Copy / Move Constructor & Assignment (복사, 이동 생성자와 대입 연산자) (0) | 2021.08.19 |
|---|---|
| [C++] Member Initializer List (멤버 초기화 리스트) (0) | 2021.08.18 |
| [C C++] Static Member Function & Static Member Variable (정적 멤버 함수 및 변수) (0) | 2021.08.16 |
| [C++] OOP Intro. 객체지향프로그래밍 (0) | 2021.08.16 |
| [C C++] String 클래스 : 기본과 메소드 (0) | 2021.08.11 |
[C++] OOP Intro. 객체지향프로그래밍
OOP Intro이기 때문에 각 특징들에 대해서 간단하게 설명한다.
C++는 객체지향 OOP (Object Oriented Programming) 언어이고 다중 패러다임 (Multi Paradigm) 프로그래밍 언어이다.
먼저 C++는 procedural, functional, OOP, generic 네 가지의 패러다임을 이용해서 프로그래밍을 하게 된다. 그중에서 OOP 특성을 중심으로 구현이 된다.
OOP란 클래스를 중심으로 프로그래밍을 하는 것을 의미한다. 클래스란 definition이라고 생각하고 그 definition으로 객체가 생성이 된다. 객체는 실제 메모리 공간을 차지하는 클래스에 대한 변수라고 생각하면 된다.
class Dog
{
public:
Dog(int age) : mAge{age} {};
private:
int mAge;
};
int main()
{
Dog choco {9}; //객체 생성
return 0;
}위 코드를 보면 "Dog"라는 클래스가 정의되었다. 클래스는 mAge라는 변수를 통해 객체의 "나이"를 저장한다. main함수에서 Dog의 Constructor를 이용하여 choco객체의 "나이"를 9로 초기화를 시켜준다.
OOP는 4개의 특성이 있다.
- Abstraction
- Encapsulation
- Inheritance
- Polymorphism
Abstraction
추상화라는 특징이다. 현실세계의 어떠한 물체 혹은 문제를 추상화를 하는 것이라고 생각하면 쉽다. 위 코드에서 현실세계에 존재하는 강아지라는 생물은 여러 특성(사족보행, 평균수명, 귀여움 등)이 있지만 현재 프로그램에서 나이만 필요할 경우 나이에 대한 멤버 변수만 생성을 해주어 강아지라는 동물을 추상화를 하여 구현한다는 특징이다.
Encapsulation
캡슐화라는 특징이다. 클래스 내부의 중요한 멤버 변수들을 외부에서 수정이 불가하도록 하는 특징이다. 예를 들면 강아지 클래스에 강아지의 평균수명 값을 저장하고 있는 멤버 변수가 있다고 가정을 해보자. 그러면 외부에서 강아지의 평균수명을 임의대로 수정을 하게 되면 문제가 생기게 된다. 캡슐화는 private, protected 등 키워드를 통해 구현이 된다. 위 코드에서 mAge 멤버 변수는 private키워드에 포함이 되기 때문에 외부에서 해당 멤버 변수를 직접 접근, 수정하는 것이 불가능하다.
Inheritance
상속성이라는 특징이다. 상속성의 가장 중요한 점은 코드의 재사용이라는 점이다. 예를 들면 현실 세계에서 강아지라는 생물은 동물에 속한다. 결국 강아지도 동물의 특성을 가지고 있다. 동물의 특성으로는 사람의 언어를 못한다는 특성이 있다고 가정하면 동물 클래스에 "사람과 대화 불가"라는 코드를 만들고 강아지 클래스에 동물 클래스를 상속을 받으면 동물 클래스의 특징을 이어받는다. 상속성을 이용해 중복되는 코드를 또 생성하지 않고 재사용할 수 있다는 장점이 있다.
Polymorphism
다형성이라는 특징이다. 다형성에는 대표적으로 function overloading과 function overriding이 있다. 다형성이라는 특징은 형태가 여러 가지 존재한다는 특징이다. 겉은 같아 보이지만 특정 파라미터 혹은 특정 상황에 맞추어 호출하는 함수가 달라지는 특징이다. 해당 특징에 대해서는 function overloading과 function overriding 포스트에서 따로 자세하게 다룰 예정이다.
우리가 c++ 프로그래밍을 하면서 유의할 점은 OOP가 목적이 되어서는 안된다는 점이다. 우리의 목적은 읽기 편하고, 이해하기 쉽고, 유지보수가 용이한 프로그램을 짜는 것이 목적이다. OOP를 정확하게 따르는 프로그램을 만드는 것이 목적이 아니다. 읽기 편하고, 이해하기 쉽고, 유지보수가 용이한 프로그램을 짜되 파포먼스까지 좋은 프로그램을 짜기 위해서 C++을 이용하는 것이다. 우리가 가장 포커스를 맞춰야 하는 점은 프로그래밍을 통해서 가치를 창출해내는 것이 우리의 목표임을 잊지 말자.
Ref.
https://www.youtube.com/channel/UCHcG02L6TSS-StkSbqVy6Fg
본 포스팅은 유튜버 코드없는프로그래밍 채널을 공부하면서 정리한 내용입니다.
'Modern C++' 카테고리의 다른 글
| [C++] Copy / Move Constructor & Assignment (복사, 이동 생성자와 대입 연산자) (0) | 2021.08.19 |
|---|---|
| [C++] Member Initializer List (멤버 초기화 리스트) (0) | 2021.08.18 |
| [C C++] Static Member Function & Static Member Variable (정적 멤버 함수 및 변수) (0) | 2021.08.16 |
| [C++] Memory Alignment (메모리 얼라인먼트) & Object In Memory (객체생성) (1) | 2021.08.16 |
| [C C++] String 클래스 : 기본과 메소드 (0) | 2021.08.11 |
[C C++] String 클래스 : 기본과 메소드
C 스타일 문자열 (char*, char [])에 익숙한 나로서 C++의 string 클래스보다 C 스타일 문자열이 아직까지 편하다. 개강도 다가오기 때문에 string 클래스에 대해서 정리를 해보자.
먼저, C 스타일 문자열의 단점에 대해서 얘기해보자.
C 스타일 문자열은 내가 저장하고자 하는 문자열의 길이보다 1 크기의 길이가 더 필요하다. 왜냐면 C 스타일 문자열에서 문자열의 끝을 나타내 주는 NULL Character ('\0')가 필요하기 때문이다. 이러한 특성 때문에 문자열의 크기에 대해서 신경을 써줘야 된다. 또한 동적으로 메모리를 할당했을 경우 할당 해제를 해주지 않으면 Memory Leak이 발생하기 쉽다.
String 클래스는 말 그대로 클래스이다. String 클래스의 객체가 우리가 통상적으로 다루게 되는 "문자열"이다. String 클래스를 사용하기 위해선 string헤더를 include 해줘야 한다. 하지만 string 헤더는 iostream 헤더에 포함되어 있기 때문에 iostream 헤더를 include 할 경우는 추가적으로 include 할 필요는 없다.
String 클래스는 기존 C 스타일 문자열에서 느낀 불편을 다소 해결해준다. NULL Character를 삽입할 필요도 없고 다양한 메서드들이 존재하고 메모리에 관해서 신경 쓸 일도 많이 줄어들었다. 하지만 C 스타일 문자열이 속도가 더 빠르다는 장점이 있다.
String 객체 생성
string str;
string str1("문자열");
string str2 = "문자열";
위와 같이 초기화 없이 str객체를 생성할 수 있다. 클래스를 공부했다면 선언과 동시에 Constructer (생성자)를 이용해 초기화하는 방법과 대입을 이용해 초기화하는 방법이 있다.
String 입력
string str;
cin >> str; //white character전까지 입력
getline(cin, str); //한 줄 통째로 입력
getline(cin, str, '문자'); //문자전까지 입력String 객체를 입력받을 때 가장 많이 이용되는 두 방법이다. 먼저 cin객체를 이용해서 입력받는 방법은 White Character (' ', '\t', '\n') 전까지 입력을 받는다는 사실을 잊지 말자. 반면에 getline함수를 이용할 경우 '\n'문자 전 즉, 한 줄을 통째로 입력을 받는다.
String 출력
String str("I love jiyong");
cout << str; //I love jiyongstring 객체의 출력은 cout 객체를 이용해 출력이 가능하다.
String의 주요 메소드
string str("Conquer");객체 str을 생성자를 이용하여 "Conquer"로 초기화.
//String 객체 인덱싱 및 특정 문자 반환
cout << str.at(5) << '\n'; //e
cout << str[5] << '\n'; //e
cout << str.front() << '\n'; //C
cout << str.back() << '\n'; //rstr객체를 at메서드를 이용하여 인덱싱 하는 방법과 배열적 용법( [] )으로 인덱싱 하는 방법이 있다. front와 back을 각각 제일 앞에 잇는 문자와 마지막 문자를 반환한다.
//String 객체 문자열 조작 메소드
str.append("문자열"); //str 뒤에 "문자열" 삽입(연결)
str.append("문자열", n, m); //"문자열"의 index : n 문자부터 m개의 문자열을 str 끝에 삽입(연결)
str.append(n, '문자'); //str 끝에 n개의 '문자' 삽입(연결)
str.insert(n, "문자열"); //index : n 문자 뒤에 "문자열" 삽입
str.replace(n, m, "문자열"); //index : n 문자부터 m개의 문자를 "문자열"로 대체
str.clear(); //문자열 모주 지움
str.erase(); //clear()과 동일
str.push_back('문자'); //문자열 맨 뒤에 '문자'삽입
str.pop_back(); //문자열 맨 뒤 문자 제거문자열을 조작하는 메소드이다. C 스타일 문자열에서 대부분 직접 구현해야 하는 기능들인데 메소드를 이용하면 편리하게 원하는 기능을 사용할 수 있다.
이외의 더 많은 메소드들이 존재한다.
본 포스트에서 다 다루지 못하고 위에 다룬 내용들도 함수의 원형 또한 모르니 레퍼런스를 꼭 참고하기 바란다.
ref.
https://www.cplusplus.com/reference/string/string/
string - C++ Reference
www.cplusplus.com
'Modern C++' 카테고리의 다른 글
| [C++] Copy / Move Constructor & Assignment (복사, 이동 생성자와 대입 연산자) (0) | 2021.08.19 |
|---|---|
| [C++] Member Initializer List (멤버 초기화 리스트) (0) | 2021.08.18 |
| [C C++] Static Member Function & Static Member Variable (정적 멤버 함수 및 변수) (0) | 2021.08.16 |
| [C++] Memory Alignment (메모리 얼라인먼트) & Object In Memory (객체생성) (1) | 2021.08.16 |
| [C++] OOP Intro. 객체지향프로그래밍 (0) | 2021.08.16 |
[Algorithm] Shell Sort (쉘 정렬) C++
Shell Sort (쉘 정렬)은 Insertion Sort (삽입 정렬)을 보완해서 나온 정렬 알고리즘이다. 삽입 정렬은 데이터가 어느 정도 정렬된 상태에서 빠른 속도를 자랑한다.
삽입 정렬의 단점은 데이터 삽입 과정에서 삽입할 위치가 멀리 있을 경우 데이터를 이동해야 하는 횟수가 늘어난다는 단점이 있다. 이 단점을 보완하여 나온 정렬 알고리즘이 쉘 알고리즘이다.
삽입 정렬은 배열의 1번째 원소부터 마지막 원소를 기준으로 잡고 좌측에 있는 원소를 하나하나 대소 비교를 통해 삽입할 위치를 찾는다. 쉘 정렬은 기준으로부터 좌측에 있는 원소와 대소 비교를 하되 gap 즉, 일정한 간격을 두고 정렬을 한다. gap을 두고 배열을 나누어 정렬한다고 생각하면 된다.

Shell Sort (쉘 정렬) 작동 방법
- 배열의 크기의 1/2를 첫 gap으로 한다. 각 gap은 홀수여야 하므로 짝수 일 경우 1을 더해 홀수로 만들어준다.
- 0번째부터 gap이전까지의 원소를 기준으로 gap만큼 떨어진 연속적이지 않은 배열로 나눈다.
- 각 연속적이지 않은 배열을 gap만큼 떨어진 원소들을 삽입 정렬로 정렬을 해준다.
- gap을 1/2배 해주어 위 과정을 gap이 0보다 클 때까지 반복한다.
Shell Sort (쉘 정렬) C++ code
#include <iostream>
using namespace std;
void ShellSort(int* arr, int n)
{
int gap, i, j, key;
for (gap = n / 2; gap > 0; gap /= 2)
{
if (gap % 2 == 0)
++gap;
for (i = gap; i <= n; ++i)
{
key = arr[i];
for (j = i; j >= gap && arr[j - gap] > key; j -= gap)
arr[j] = arr[j - gap];
arr[j] = key;
}
}
}
int main()
{
int arr[15] = { 4, 8, 3, 6, 2, 1, 13, 15, 37, 56, 4, 2, 46, 24, 99};
for (int i = 0; i < 15; ++i)
cout << arr[i] << ' ';
ShellSort(arr, 14);
cout << '\n';
for (int i = 0; i < 15; ++i)
cout << arr[i] << ' ';
}
Ref.
쉘 정렬 / https://gmlwjd9405.github.io/2018/05/08/algorithm-shell-sort.html
Shell Sort / https://en.wikipedia.org/wiki/Shellsort
'Algorithm' 카테고리의 다른 글
| [Algorithm] Quick Sort (퀵 정렬) C++ (0) | 2021.08.01 |
|---|---|
| [Algorithm] Merge Sort (합병 정렬) C++ (0) | 2021.07.25 |
| [Algorithm] Bubble Sort (버블 소트) C++ (0) | 2021.07.23 |
| [Algorithm] Selection Sort (선택 정렬) C++ (0) | 2021.07.22 |
| [Algorithm] Insertion Sort (삽입 정렬) C++ (0) | 2021.07.20 |
[Verilog] 32bit RCA (Ripple Carry Adder) : 32비트 가산기
RCA란 Ripple Carry Adder의 약자로 1비트 가산기에서 생성된 carry(자리 올림수)를 ripple(물결)처럼 계속 넘기는 것을 반복한다고 해서 Ripple Carry Adder라는 이름이 붙여졌다.
4bit RCA의 구성

각 비트의 합은 1-bit Full Adder로 연산이 된다 LSB(Least Significant Bit)의 연산에서 Carry in을 받고 다음 Full Adder에게 Carry out을 넘겨준다.
다음 비트는 LSB의 연산에서 나온 Carry out을 Carry in을 입력으로 받고 다음 해당 비트의 Carry out을 다음 비트에 넘겨준다. 이 과정은 MSB(Most Significant Bit)까지 반복을 하고 MSB의 Carry out은 해당 RCA 4비트의 최종적 Carry out이 된다.
32bit RCA의 경우는 위 과정을 32번 반복한다고 생각하면 된다.
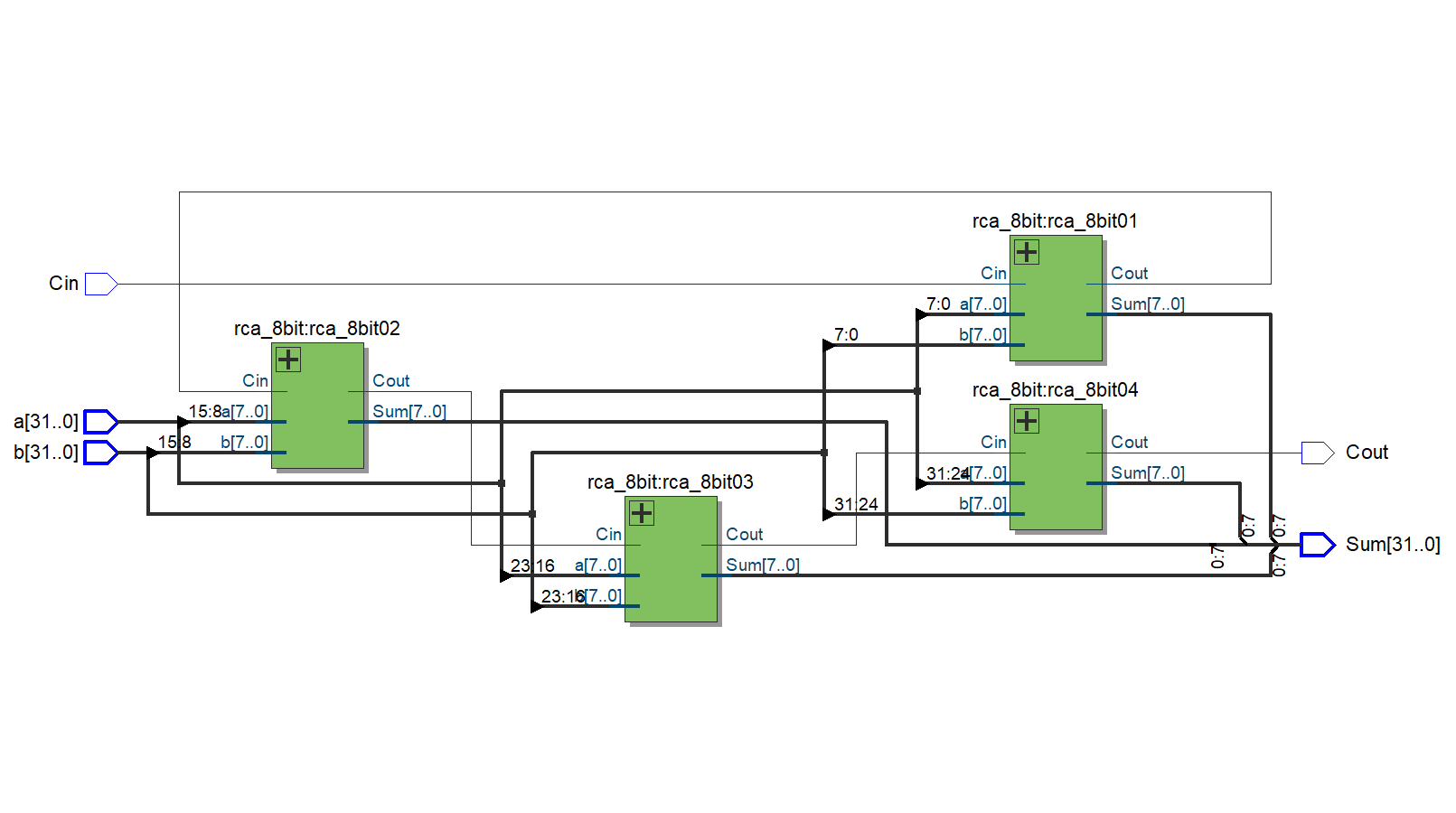
32bit RCA RTL view
32bit RCA Verilog HDL code
module rca_32bit(a, b, Cin, Sum, Cout);
input [31:0] a, b;
input Cin;
output [31:0] Sum;
output Cout;
wire [2:0] Carry;
rca_8bit rca_8bit01(.a(a[7:0]), .b(b[7:0]), .Cin(Cin), .Sum(Sum[7:0]), .Cout(Carry[0]));
rca_8bit rca_8bit02(.a(a[15:8]), .b(b[15:8]), .Cin(Carry[0]), .Sum(Sum[15:8]), .Cout(Carry[1]));
rca_8bit rca_8bit03(.a(a[23:16]), .b(b[23:16]), .Cin(Carry[1]), .Sum(Sum[23:16]), .Cout(Carry[2]));
rca_8bit rca_8bit04(.a(a[31:24]), .b(b[31:24]), .Cin(Carry[2]), .Sum(Sum[31:24]), .Cout(Cout));
endmodule
module HalfAdder(a, b, Sum, Cout);
input a, b;
output Sum, Cout;
assign Sum = a ^ b;
assign Cout = a & b;
endmodule
module FullAdder(a, b, Cin, Sum, Cout);
input a, b, Cin;
output Sum, Cout;
wire Sum01, Carry01, Carry02;
HalfAdder HA01(.a(a), .b(b), .Sum(Sum01), .Cout(Carry01));
HalfAdder HA02(.a(Sum01), .b(Cin), .Sum(Sum), .Cout(Carry02));
assign Cout = Carry01 | Carry02;
endmodule
module rca_4bit(a, b, Cin, Sum, Cout);
input [3:0] a, b;
input Cin;
output [3:0] Sum;
output Cout;
wire [2:0] Carry;
FullAdder FA01(.a(a[0]), .b(b[0]), .Cin(Cin), .Sum(Sum[0]), .Cout(Carry[0]));
FullAdder FA02(.a(a[1]), .b(b[1]), .Cin(Carry[0]), .Sum(Sum[1]), .Cout(Carry[1]));
FullAdder FA03(.a(a[2]), .b(b[2]), .Cin(Carry[1]), .Sum(Sum[2]), .Cout(Carry[2]));
FullAdder FA04(.a(a[3]), .b(b[3]), .Cin(Carry[2]), .Sum(Sum[3]), .Cout(Cout));
endmodule
module rca_8bit(a, b, Cin, Sum, Cout);
input [7:0] a, b;
input Cin;
output [7:0] Sum;
output Cout;
wire Carry;
rca_4bit rca_4bit01(.a(a[3:0]), .b(b[3:0]), .Cin(Cin), .Sum(Sum[3:0]), .Cout(Carry));
rca_4bit rca_4bit02(.a(a[7:4]), .b(b[7:4]), .Cin(Carry), .Sum(Sum[7:4]), .Cout(Cout));
endmodule
필자는 Half Adder로 Full Adder 모듈을 만들었다 (뇌피셜 - 대체적으로 이렇게 만들더라). 그다음 Full Adder 4개를 이용하여 4비트 RCA 모듈을 만들었다. 그다음 4비트 RCA 2개를 이용해 8비트 RCA를 만들었다.
32비트 RCA를 Full Adder로 만드는 법은 Full Adder 32개를 이어주는 방법이 가장 쉽고 직관적인 방법이다.
32bit RCA Verilog HDL code (with 32 Full Adders)
module rca_32bit(a, b, Cin, Sum, Cout);
input [31:0] a, b;
input Cin;
output [31:0] Sum;
output Cout;
wire [2:0] Carry;
fulladder fulladder_0(.a(a[0]), .b(b[0]), .Cin(Cin), .Sum(Sum[0]), .Cout(Carry[0])); //connect input and output, it generateSum Carry
fulladder fulladder_1(.a(a[1]), .b(b[1]), .Cin(Carry[0]), .Sum(Sum[1]), .Cout(Carry[1])); //connect input Cin with Carry that generated Carry in 0-bit poSumition
fulladder fulladder_2(.a(a[2]), .b(b[2]), .Cin(Carry[1]), .Sum(Sum[2]), .Cout(Carry[2]));
fulladder fulladder_3(.a(a[3]), .b(b[3]), .Cin(Carry[2]), .Sum(Sum[3]), .Cout(Carry[3]));
//4bit adder
fulladder fulladder_4(.a(a[4]), .b(b[4]), .Cin(Carry[3]), .Sum(Sum[4]), .Cout(Carry[4]));
fulladder fulladder_5(.a(a[5]), .b(b[5]), .Cin(Carry[4]), .Sum(Sum[5]), .Cout(Carry[5]));
fulladder fulladder_6(.a(a[6]), .b(b[6]), .Cin(Carry[5]), .Sum(Sum[6]), .Cout(Carry[6]));
fulladder fulladder_7(.a(a[7]), .b(b[7]), .Cin(Carry[6]), .Sum(Sum[7]), .Cout(Carry[7]));
//4bit adder
fulladder fulladder_8(.a(a[8]), .b(b[8]), .Cin(Carry[7]), .Sum(Sum[8]), .Cout(Carry[8]));
fulladder fulladder_9(.a(a[9]), .b(b[9]), .Cin(Carry[8]), .Sum(Sum[9]), .Cout(Carry[9]));
fulladder fulladder_10(.a(a[10]), .b(b[10]), .Cin(Carry[9]), .Sum(Sum[10]), .Cout(Carry[10]));
fulladder fulladder_11(.a(a[11]), .b(b[11]), .Cin(Carry[10]), .Sum(Sum[11]), .Cout(Carry[11]));
//4bit adder
fulladder fulladder_12(.a(a[12]), .b(b[12]), .Cin(Carry[11]), .Sum(Sum[12]), .Cout(Carry[12]));
fulladder fulladder_13(.a(a[13]), .b(b[13]), .Cin(Carry[12]), .Sum(Sum[13]), .Cout(Carry[13]));
fulladder fulladder_14(.a(a[14]), .b(b[14]), .Cin(Carry[13]), .Sum(Sum[14]), .Cout(Carry[14]));
fulladder fulladder_15(.a(a[15]), .b(b[15]), .Cin(Carry[14]), .Sum(Sum[15]), .Cout(Carry[15]));
//4bit adder
fulladder fulladder_16(.a(a[16]), .b(b[16]), .Cin(Carry[15]), .Sum(Sum[16]), .Cout(Carry[16]));
fulladder fulladder_17(.a(a[17]), .b(b[17]), .Cin(Carry[16]), .Sum(Sum[17]), .Cout(Carry[17]));
fulladder fulladder_18(.a(a[18]), .b(b[18]), .Cin(Carry[17]), .Sum(Sum[18]), .Cout(Carry[18]));
fulladder fulladder_19(.a(a[19]), .b(b[19]), .Cin(Carry[18]), .Sum(Sum[19]), .Cout(Carry[19]));
//4bit adder
fulladder fulladder_20(.a(a[20]), .b(b[20]), .Cin(Carry[19]), .Sum(Sum[20]), .Cout(Carry[20]));
fulladder fulladder_21(.a(a[21]), .b(b[21]), .Cin(Carry[20]), .Sum(Sum[21]), .Cout(Carry[21]));
fulladder fulladder_22(.a(a[22]), .b(b[22]), .Cin(Carry[21]), .Sum(Sum[22]), .Cout(Carry[22]));
fulladder fulladder_23(.a(a[23]), .b(b[23]), .Cin(Carry[22]), .Sum(Sum[23]), .Cout(Carry[23]));
//4bit adder
fulladder fulladder_24(.a(a[24]), .b(b[24]), .Cin(Carry[23]), .Sum(Sum[24]), .Cout(Carry[24]));
fulladder fulladder_25(.a(a[25]), .b(b[25]), .Cin(Carry[24]), .Sum(Sum[25]), .Cout(Carry[25]));
fulladder fulladder_26(.a(a[26]), .b(b[26]), .Cin(Carry[25]), .Sum(Sum[26]), .Cout(Carry[26]));
fulladder fulladder_27(.a(a[27]), .b(b[27]), .Cin(Carry[26]), .Sum(Sum[27]), .Cout(Carry[27]));
//4bit adder
fulladder fulladder_28(.a(a[28]), .b(b[28]), .Cin(Carry[27]), .Sum(Sum[28]), .Cout(Carry[28]));
fulladder fulladder_29(.a(a[29]), .b(b[29]), .Cin(Carry[28]), .Sum(Sum[29]), .Cout(Carry[29]));
fulladder fulladder_30(.a(a[30]), .b(b[30]), .Cin(Carry[29]), .Sum(Sum[30]), .Cout(Carry[30]));
fulladder fulladder_31(.a(a[31]), .b(b[31]), .Cin(Carry[30]), .Sum(Sum[31]), .Cout(Cout));
endmodule
[Algorithm] Quick Sort (퀵 정렬) C++
평균적으로 빠른 속도를 자랑하는 정렬 알고리즘이다.
퀵 정렬은 Merge Sort (합병 정렬)과 같이 divide and conquer (분할 정복) 알고리즘이다.
같은 분할 정복 알고리즘인 합병 정렬과는 다르게 In-place 알고리즘이다. 하지만 여전히 재귀 호출로 인한 스택 메모리 공간이 필요하기 때문에 $O$($logn$)의 공간 복잡도를 가진다.
퀵 정렬은 합병 정렬과 다르게 추가적인 메모리 공간이 필요 없다. 또한 퀵 정렬은 균등하게(반으로) 분할하는 합병 정렬과 다르게 비균등하게 분할을 하게 된다.
퀵 정렬을 정렬 알고리즘에서 빠른 속도를 내주는 알고리즘이다. 피벗(기준)을 어디로 잡느냐에 따라 달라지지만 평균적으로 $O$($nlogn$)의 시간 복잡도를 가진다.

퀵 정렬은 pivot을 사용하게 된다. pivot은 분할을 할 때 기준이 되고 분할을 한 후 대소 비교의 기준이 된다. 쉽게 기준이라고 생각하면 쉽다. pivot을 어떻게 설정하냐에 따라 알고리즘의 속도가 달라질 수 있다. pivot설정에 대해서 아직도 연구 중이며 본 퀵 정렬의 pivot은 최좌단 원소로 한다.
퀵 정렬 작동 방법
- 배열의 맨 왼쪽 원소를 pivot으로 설정하고 pivot기준 왼쪽엔 pivot 보다 작은 원소 오른쪽엔 pivot 보다 큰 원소로 위치한다.
- pivot기준 좌측과 우측을 동일한 방법으로 분할하여 정렬한다.
- 위 과정을 분할하여 정렬하고자 하는 배열의 크기가 1보다 작거나 같은 경우전까지 반복한다.
Quick Sort (퀵 정렬) C++ 코드
#include <iostream>
using namespace std;
void SWAP(int* a, int* b)
{
int temp = *a;
*a = *b;
*b = temp;
}
int quick_sort(int* arr, int left, int right)
{
int pivot;
int low, high;
pivot = arr[left];
low = left + 1;
high = right;
while (low <= high)
{
while (arr[low] <= pivot && low <= right)
{
++low;
}
while (arr[high] => pivot && high >= left + 1)
{
--high;
}
if (low <= high)
{
SWAP(&arr[low], &arr[high]);
}
}
SWAP(&arr[left], &arr[high]);
return high;
}
void partition(int* arr, int left, int right)
{
if (left < right)
{
int q = quick_sort(arr, left, right);
partition(arr, left, q - 1);
partition(arr, q + 1, right);
}
}
int main()
{
int arr[10] = { 3, -1, 2, 9, 13, 29, 94, 29 ,9, 11 };
for (int i = 0; i < 10; ++i)
cout << arr[i] << " ";
partition(arr, 0, 9);
cout << "\n";
for (int i = 0; i < 10; ++i)
cout << arr[i] << " ";
}
Ref.
Quick Sort / https://en.wikipedia.org/wiki/Quicksort
'Algorithm' 카테고리의 다른 글
| [Algorithm] Shell Sort (쉘 정렬) C++ (0) | 2021.08.08 |
|---|---|
| [Algorithm] Merge Sort (합병 정렬) C++ (0) | 2021.07.25 |
| [Algorithm] Bubble Sort (버블 소트) C++ (0) | 2021.07.23 |
| [Algorithm] Selection Sort (선택 정렬) C++ (0) | 2021.07.22 |
| [Algorithm] Insertion Sort (삽입 정렬) C++ (0) | 2021.07.20 |
[백준] 1978번 : 소수 찾기 C++
소수(prime number)를 찾는 문제이다.
문제 분석 및 접근 방법
주어진 N개의 수 중에 소수가 몇 개 있는지를 출력하는 프로그램이다. 해당 문제는 소수를 판단하는 알고리즘을 짜는 것이 문제이고 알고리즘을 어떻게 짜야지 효율적인지 생각을 한다.
먼저 소수의 수학적 정의를 상기하고 수학적 정의를 바탕으로 알고리즘을 작성하고 더 효율적인 방법이 있는지 생각해본다.
소수의 정의 (Prime number)
1보다 큰 자연수 중 1과 자신만을 약수로 가지는 수를 말한다.
소수를 찾는 방법은 크게 3가지가 있다.
- 2부터 해당 정수까지 반복문을 통하여 나누어 떨어지는 정수가 존재하는지를 찾는다.
- 2부터 해당 정수의 제곱근까지 반복문을 통하여 나누어 떨어지는 정수가 존재하는지를 찾는다.
첫 번째 경우
정의대로 for문을 통하여 2부터 자신까지 반복문을 통해 해당 정수를 나누었을 때 나누어 떨어지는 수가 있는지 확인한다. 이런 경우는 해당 정수가 $n$이라고 가정하면 $n$번 반복이 일어나므로 시간 복잡도는 $O$($n$)이다.
bool isPrimeNumber(int checknum)
{
if (checknum == 1)
return false;
int i;
for(i = 2; i <= checksum; ++i)
{
if (checknum % i == 0)
{
return false;
}
}
return true;
}
두 번째 경우
두 번째 경우는 약수의 특성을 이용하는 방법이다. 어떤 정수의 약수는 제곱근을 기준으로 대칭을 이루게 된다. 예를 들면 12의 약수는 1, 2, 3, 4, 6, 12이다. 1 * 12, 2 * 6, 3 * 6으로 제곱근을 기준으로 좌우측 약수들이 대칭으로 곱해져야 정수가 된다. 또한, 소수는 2 이상 해당 정수 이하에 약수가 하나라도 존재하면 안 되기 때문에 반복문의 범위를 제곱 근수까지 줄여서 알고리즘의 효율을 높일 수 있다. 시간 복잡도는 $O$($n^½$)가 된다.
bool isPrimeNumber(int checknum)
{
int root = (int)sqrt(checknum);
if (checknum == 1)
return false;
int i;
for(i = 2; i <= root; ++i)
{
if (checknum % i == 0)
{
return false;
}
}
return true;
}
* sqrt()
해당 함수는 ctime 헤더에 존대하는 함수이다.
함수원형은 double sqrt(double)이다. 따라서 반환되는 값이 double형이기 때문에 integer형 변수 root에 type casting(형 변환)을 해주었다. 또한 integer형 매개변수 checknum은 sqrt함수에 전달될 시 자동으로 type casting이 된다.
소수를 구하는 방법에는 에라토스테네스의 체라는 방법이 존재한다. 해당 방법은 백준 1929번 : 소수 구하기 문제에서 다루도록 한다.
[Algorithm] Merge Sort (합병 정렬) C++
본 블로그에서 이미 다룬 선택, 삽입, 버블 정렬 돠 비교하면 이해하기 다소 높은 정렬 알고리즘이라고 할 수 있다.
합병 정렬은 divide and conquer (분할 정복) 알고리즘을 기반으로 정렬을 하는 알고리즘이다.
Divide and conquer 알고리즘은 큰 문제를 작은 문제들로 쪼개서 해결하는 방식이다. 합병 정렬에서는 배열을 계속 쪼개 작은 행렬들을 정렬하고 그 행렬들을 합쳐 정렬을 진행한다. (해당 알고리즘에 대해서 따로 포스팅할 예정이다).
합병 정렬은 정렬을 하는 배열외의 추가적인 임시 배열 (추가적인 메모리)가 필요하다. 삽입, 버블, 선택 정렬의 공간 복잡도 $O$($1$) 과 다르게 합병 정렬은 정렬하고자 하는 배열의 크기만큼의 추가적인 크기가 요구되기 때문에 $O$($n$)의 공간복잡도를 가진다. 또한 In-place 알고리즘이 아니다.
합병 정렬은 배열은 $log$ $n$번 쪼개어 대수 비교를 하기 때문에 시간 복잡도는 $O$($nlog$ $n$)이다. 예를 들어 원소가 8개인 배열을 중간 원소를 기준으로 3번 쪼개면 8개 원소가 1개씩으로 쪼개진다.
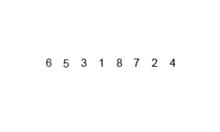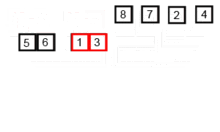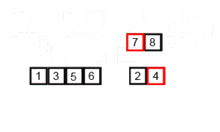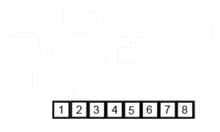
합병 정렬의 작동 방법
- 배열을 원소의 개수가 1인 그룹으로 재귀적 호출을 이용해 나눈다.
- 인접한 그룹을 의 첫번째 원소부터 끝 원소까지 대소 비교를 하여 정렬된 하나의 그룹을 만든다. 정렬된 새로운 그룹(배열)을 전역 변수 정수형 임시 배열에 저장한다.
- 전역 변수 정수형 임시 배열을 원래 배열에 복사한다.
합병 정렬 추천 이해 루트
필자는 머리가 나쁘기 때문에 머지 소트를 이했던 방법에 대해서 설명한다.
- 배열이 재귀호출로 분할되는 과정을 이해한다.
- 재귀호출로 스택에 쌓이는 순서를 이해한다.
- 작게 쪼개진 배열의 대소비교를 이해한다.
배열의 대소비교 로직은 쉬우니 재귀호출이 스택에 어떻게 쌓이고 어떤 순서로 대소비교가 되는지를 알면 합병 정렬을 이해하기 쉽다.
합병 정렬의 시간, 공간 복잡도
| 시간 복잡도 | 공간 복잡도 | ||
| 평균 (Average) | 최선 (Best) | 최악 (Worst) | |
| $O$($nlog$ $n$) | $O$($nlog$ $n$) | $O$($nlog$ $n$) | $O$($n$) |
Merge Sort (합병 정렬) C++ 코드
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int* sorted;
void merge(int* arr, int left, int right)
{
int mid = (left + right) / 2;
int i = left;
int j = mid + 1;
//i ~ mid을 한 그룹 mid + 1 ~ right를 한 그룹으로 나눠서 처리.
int index_sorted = left;
while (i <= mid && j <= right)
{
if (arr[i] > arr[j])
{
sorted[index_sorted++] = arr[j++];
}
else
{
sorted[index_sorted++] = arr[i++];
}
}
if (i > mid)
{
while (j <= right)
{
sorted[index_sorted++] = arr[j++];
}
}
else
{
while (i <= mid)
{
sorted[index_sorted++] = arr[i++];
}
}
//arr에 재배치된 배열 업데이트
for (int a = left; a <= right; ++a)
{
arr[a] = sorted[a];
}
}
void partition(int* arr, int left, int right)
{
int mid;
if (left < right)
{
mid = (left + right) / 2;
partition(arr, left, mid);
partition(arr, mid + 1, right);
merge(arr, left, right);
}
}
int main()
{
int* arr;
srand(unsigned int(time(NULL)));
int amount;
cout << "amout : ";
cin >> amount;
arr = new int[amount];
sorted = new int[amount];
int i;
for (i = 0; i < amount; ++i)
{
arr[i] = rand() % 10;
sorted[i] = 0;
}
for (i = 0; i < amount; ++i)
cout << arr[i] << " ";
cout << '\n';
partition(arr, 0, amount - 1);
for (i = 0; i < amount; ++i)
cout << arr[i] << " ";
cout << '\n';
}
고찰
divide and conquer에 대해서 처음 배우게 되어서 조금 시간이 많이 걸렸다. 먼저 재귀함수에 대해서 전체적으로 돌아가는 로직은 알았으나 세부적으로 스택에 어떻게 쌓여서 어떤 우선순위로 일이 처리되는지 잘 이해하지 못해서 조금 힘들었다. 해당 정렬을 정리하면서 스택의 LIFO에 대해서도 조금 더 알게 되었다.
Ref.
Merge Sort / https://en.wikipedia.org/wiki/Merge_sort
'Algorithm' 카테고리의 다른 글
| [Algorithm] Shell Sort (쉘 정렬) C++ (0) | 2021.08.08 |
|---|---|
| [Algorithm] Quick Sort (퀵 정렬) C++ (0) | 2021.08.01 |
| [Algorithm] Bubble Sort (버블 소트) C++ (0) | 2021.07.23 |
| [Algorithm] Selection Sort (선택 정렬) C++ (0) | 2021.07.22 |
| [Algorithm] Insertion Sort (삽입 정렬) C++ (0) | 2021.07.20 |