[Algorithm] Merge Sort (합병 정렬) C++
본 블로그에서 이미 다룬 선택, 삽입, 버블 정렬 돠 비교하면 이해하기 다소 높은 정렬 알고리즘이라고 할 수 있다.
합병 정렬은 divide and conquer (분할 정복) 알고리즘을 기반으로 정렬을 하는 알고리즘이다.
Divide and conquer 알고리즘은 큰 문제를 작은 문제들로 쪼개서 해결하는 방식이다. 합병 정렬에서는 배열을 계속 쪼개 작은 행렬들을 정렬하고 그 행렬들을 합쳐 정렬을 진행한다. (해당 알고리즘에 대해서 따로 포스팅할 예정이다).
합병 정렬은 정렬을 하는 배열외의 추가적인 임시 배열 (추가적인 메모리)가 필요하다. 삽입, 버블, 선택 정렬의 공간 복잡도 $O$($1$) 과 다르게 합병 정렬은 정렬하고자 하는 배열의 크기만큼의 추가적인 크기가 요구되기 때문에 $O$($n$)의 공간복잡도를 가진다. 또한 In-place 알고리즘이 아니다.
합병 정렬은 배열은 $log$ $n$번 쪼개어 대수 비교를 하기 때문에 시간 복잡도는 $O$($nlog$ $n$)이다. 예를 들어 원소가 8개인 배열을 중간 원소를 기준으로 3번 쪼개면 8개 원소가 1개씩으로 쪼개진다.
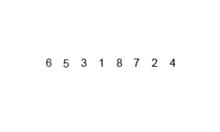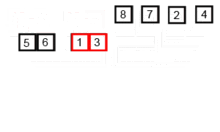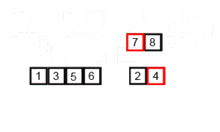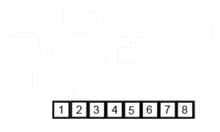
합병 정렬의 작동 방법
- 배열을 원소의 개수가 1인 그룹으로 재귀적 호출을 이용해 나눈다.
- 인접한 그룹을 의 첫번째 원소부터 끝 원소까지 대소 비교를 하여 정렬된 하나의 그룹을 만든다. 정렬된 새로운 그룹(배열)을 전역 변수 정수형 임시 배열에 저장한다.
- 전역 변수 정수형 임시 배열을 원래 배열에 복사한다.
합병 정렬 추천 이해 루트
필자는 머리가 나쁘기 때문에 머지 소트를 이했던 방법에 대해서 설명한다.
- 배열이 재귀호출로 분할되는 과정을 이해한다.
- 재귀호출로 스택에 쌓이는 순서를 이해한다.
- 작게 쪼개진 배열의 대소비교를 이해한다.
배열의 대소비교 로직은 쉬우니 재귀호출이 스택에 어떻게 쌓이고 어떤 순서로 대소비교가 되는지를 알면 합병 정렬을 이해하기 쉽다.
합병 정렬의 시간, 공간 복잡도
| 시간 복잡도 | 공간 복잡도 | ||
| 평균 (Average) | 최선 (Best) | 최악 (Worst) | |
| $O$($nlog$ $n$) | $O$($nlog$ $n$) | $O$($nlog$ $n$) | $O$($n$) |
Merge Sort (합병 정렬) C++ 코드
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int* sorted;
void merge(int* arr, int left, int right)
{
int mid = (left + right) / 2;
int i = left;
int j = mid + 1;
//i ~ mid을 한 그룹 mid + 1 ~ right를 한 그룹으로 나눠서 처리.
int index_sorted = left;
while (i <= mid && j <= right)
{
if (arr[i] > arr[j])
{
sorted[index_sorted++] = arr[j++];
}
else
{
sorted[index_sorted++] = arr[i++];
}
}
if (i > mid)
{
while (j <= right)
{
sorted[index_sorted++] = arr[j++];
}
}
else
{
while (i <= mid)
{
sorted[index_sorted++] = arr[i++];
}
}
//arr에 재배치된 배열 업데이트
for (int a = left; a <= right; ++a)
{
arr[a] = sorted[a];
}
}
void partition(int* arr, int left, int right)
{
int mid;
if (left < right)
{
mid = (left + right) / 2;
partition(arr, left, mid);
partition(arr, mid + 1, right);
merge(arr, left, right);
}
}
int main()
{
int* arr;
srand(unsigned int(time(NULL)));
int amount;
cout << "amout : ";
cin >> amount;
arr = new int[amount];
sorted = new int[amount];
int i;
for (i = 0; i < amount; ++i)
{
arr[i] = rand() % 10;
sorted[i] = 0;
}
for (i = 0; i < amount; ++i)
cout << arr[i] << " ";
cout << '\n';
partition(arr, 0, amount - 1);
for (i = 0; i < amount; ++i)
cout << arr[i] << " ";
cout << '\n';
}
고찰
divide and conquer에 대해서 처음 배우게 되어서 조금 시간이 많이 걸렸다. 먼저 재귀함수에 대해서 전체적으로 돌아가는 로직은 알았으나 세부적으로 스택에 어떻게 쌓여서 어떤 우선순위로 일이 처리되는지 잘 이해하지 못해서 조금 힘들었다. 해당 정렬을 정리하면서 스택의 LIFO에 대해서도 조금 더 알게 되었다.
Ref.
Merge Sort / https://en.wikipedia.org/wiki/Merge_sort
'Algorithm' 카테고리의 다른 글
| [Algorithm] Shell Sort (쉘 정렬) C++ (0) | 2021.08.08 |
|---|---|
| [Algorithm] Quick Sort (퀵 정렬) C++ (0) | 2021.08.01 |
| [Algorithm] Bubble Sort (버블 소트) C++ (0) | 2021.07.23 |
| [Algorithm] Selection Sort (선택 정렬) C++ (0) | 2021.07.22 |
| [Algorithm] Insertion Sort (삽입 정렬) C++ (0) | 2021.07.20 |